


















- Bài 1: Tìm hiểu về pandas
- Bài 2: Hướng dẫn cài đặt pandas
- Bài 3: Giới thiệu về cấu trúc dữ liệu
- Bài 4: Series
- Bài 5: DataFrame
- Bài 6: Panel
- Bài 7: Hàm cơ bản - Series
- Bài 8: Các hàm cơ bản : DataFrame
- Bài 9: Thống kê
- Bài 10: Ứng dụng Hàm
- Bài 11: Đọc dữ liệu và kĩ thuật reindexing
- Bài 12: Iteration ( Duyệt phần tử)
- Bài 13: Sort ( Sắp xếp )
- Bài 14: Làm việc với dữ liệu Text (P1)
- Bài 15: Làm việu với dữ liệu Text (p2)
- Bài 16: Options và Customize
- Bài 17: Data Selection và Indexing trong Pandas - p1
- Bài 18: Data Selection và Indexing trong Pandas - p2
- Bài 19: Hàm thống kê
- Bài 20: Hàm Window
- Bài 21: Aggregate
- Bài 22: Missing Data ( Thiếu dữ liệu )
- Bài 23: GroupBy (Nhóm dữ liệu) - p1
- Bài 24: GroupBy (Nhóm dữ liệu)- P2
- Bài 25: Joining/merging
Bài 9: Thống kê - Python Panda
Đăng bởi: Admin | Lượt xem: 2572 | Chuyên mục: Python
Một số lượng lớn các phương pháp tính toán thống kê mô tả và các hoạt động liên quan khác trên DataFrame. Hầu hết chúng là các tổng hợp như sum (), mean (), nhưng một số trong số chúng, như sumsum (), tạo ra một đối tượng có cùng kích thước. Nói chung, các phương thức này nhận đối số trục, giống như ndarray. {Sum, std, ...}, nhưng trục có thể được chỉ định bằng tên hoặc số nguyên
DataFrame − “index” (axis=0, default), “columns” (axis=1)
Ta hãy tạo một DataFrame và sử dụng đối tượng này trong suốt bài này
Ví dụ :
import pandas as pd
import numpy as np
#Create a Dictionary of series
d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack',
'Lee','David','Gasper','Betina','Andres']),
'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]),
'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65])
}
#Create a DataFrame
df = pd.DataFrame(d)
print dfKết quả :
Age Name Rating
0 25 Tom 4.23
1 26 James 3.24
2 25 Ricky 3.98
3 23 Vin 2.56
4 30 Steve 3.20
5 29 Smith 4.60
6 23 Jack 3.80
7 34 Lee 3.78
8 40 David 2.98
9 30 Gasper 4.80
10 51 Betina 4.10
11 46 Andres 3.651. sum()
Trả về tổng các giá trị cho trục được yêu cầu. Theo mặc định, trục là chỉ số (trục = 0)
import pandas as pd
import numpy as np
#Create a Dictionary of series
d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack',
'Lee','David','Gasper','Betina','Andres']),
'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]),
'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65])
}
#Create a DataFrame
df = pd.DataFrame(d)
print df.sum()Kết quả :
Age 382
Name TomJamesRickyVinSteveSmithJackLeeDavidGasperBe...
Rating 44.92
dtype: objectaxis = 1
Cú pháp này sẽ cho kết quả như hình dưới đây.
import pandas as pd
import numpy as np
#Create a Dictionary of series
d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack',
'Lee','David','Gasper','Betina','Andres']),
'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]),
'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65])
}
#Create a DataFrame
df = pd.DataFrame(d)
print df.sum(1)Kết quả :
0 29.23
1 29.24
2 28.98
3 25.56
4 33.20
5 33.60
6 26.80
7 37.78
8 42.98
9 34.80
10 55.10
11 49.65
dtype: float64mean()
Trả về giá trị trung bình
import pandas as pd
import numpy as np
#Create a Dictionary of series
d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack',
'Lee','David','Gasper','Betina','Andres']),
'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]),
'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65])
}
#Create a DataFrame
df = pd.DataFrame(d)
print df.mean()Kết quả :
Age 31.833333
Rating 3.743333
dtype: float64std()
Trả về độ lệch chuẩn Bressel của các cột số.
import pandas as pd
import numpy as np
#Create a Dictionary of series
d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack',
'Lee','David','Gasper','Betina','Andres']),
'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]),
'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65])
}
#Create a DataFrame
df = pd.DataFrame(d)
print df.std()Kết quả :
Age 9.232682
Rating 0.661628
dtype: float64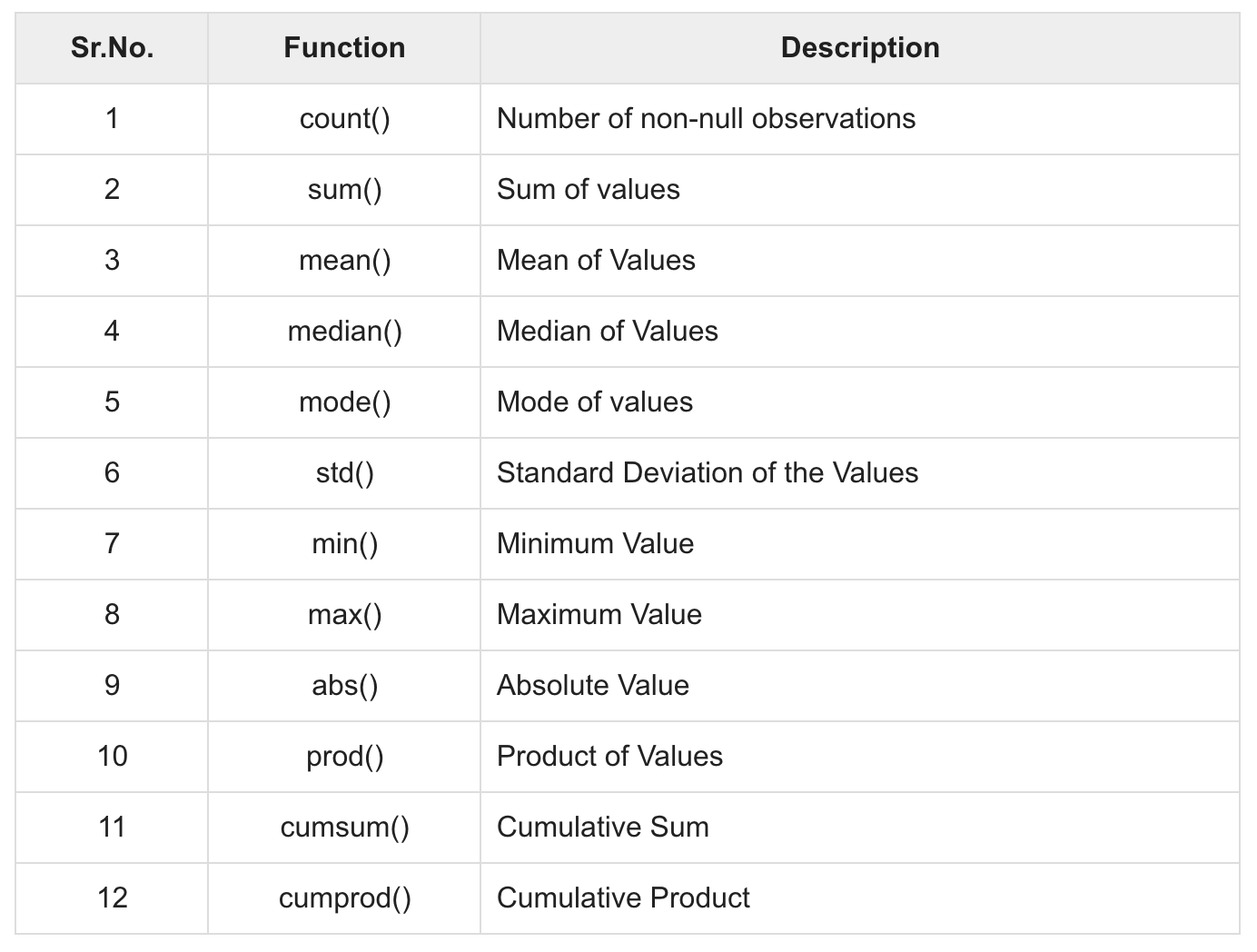
Tổng hợp dữ liệu :
Hàm description () tính toán một bản tóm tắt thống kê liên quan đến các cột DataFrame.
import pandas as pd
import numpy as np
#Create a Dictionary of series
d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack',
'Lee','David','Gasper','Betina','Andres']),
'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]),
'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65])
}
#Create a DataFrame
df = pd.DataFrame(d)
print df.describe()Kết quả :
Age Rating
count 12.000000 12.000000
mean 31.833333 3.743333
std 9.232682 0.661628
min 23.000000 2.560000
25% 25.000000 3.230000
50% 29.500000 3.790000
75% 35.500000 4.132500
max 51.000000 4.800000Hàm này cung cấp các giá trị trung bình, std và IQR. Và, hàm loại trừ các cột ký tự và tóm tắt đã cho về các cột số. 'include' là đối số được sử dụng để chuyển thông tin cần thiết về những cột nào cần được xem xét để tóm tắt. Lấy danh sách các giá trị; theo mặc định, 'number'.
- object
- number
- all
Ví dụ sau để kiểm tra kết quả :
import pandas as pd
import numpy as np
#Create a Dictionary of series
d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack',
'Lee','David','Gasper','Betina','Andres']),
'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]),
'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65])
}
#Create a DataFrame
df = pd.DataFrame(d)
print df.describe(include=['object'])Kết quả :
Name
count 12
unique 12
top Ricky
freq 1import pandas as pd
import numpy as np
#Create a Dictionary of series
d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack',
'Lee','David','Gasper','Betina','Andres']),
'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]),
'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65])
}
#Create a DataFrame
df = pd.DataFrame(d)
print df. describe(include='all')Kết quả :
Age Name Rating
count 12.000000 12 12.000000
unique NaN 12 NaN
top NaN Ricky NaN
freq NaN 1 NaN
mean 31.833333 NaN 3.743333
std 9.232682 NaN 0.661628
min 23.000000 NaN 2.560000
25% 25.000000 NaN 3.230000
50% 29.500000 NaN 3.790000
75% 35.500000 NaN 4.132500
max 51.000000 NaN 4.800000Theo dõi VnCoder trên Facebook, để cập nhật những bài viết, tin tức và khoá học mới nhất!
- Bài 1: Tìm hiểu về pandas
- Bài 2: Hướng dẫn cài đặt pandas
- Bài 3: Giới thiệu về cấu trúc dữ liệu
- Bài 4: Series
- Bài 5: DataFrame
- Bài 6: Panel
- Bài 7: Hàm cơ bản - Series
- Bài 8: Các hàm cơ bản : DataFrame
- Bài 9: Thống kê
- Bài 10: Ứng dụng Hàm
- Bài 11: Đọc dữ liệu và kĩ thuật reindexing
- Bài 12: Iteration ( Duyệt phần tử)
- Bài 13: Sort ( Sắp xếp )
- Bài 14: Làm việc với dữ liệu Text (P1)
- Bài 15: Làm việu với dữ liệu Text (p2)
- Bài 16: Options và Customize
- Bài 17: Data Selection và Indexing trong Pandas - p1
- Bài 18: Data Selection và Indexing trong Pandas - p2
- Bài 19: Hàm thống kê
- Bài 20: Hàm Window
- Bài 21: Aggregate
- Bài 22: Missing Data ( Thiếu dữ liệu )
- Bài 23: GroupBy (Nhóm dữ liệu) - p1
- Bài 24: GroupBy (Nhóm dữ liệu)- P2
- Bài 25: Joining/merging