OCR dựa trên nền tảng Deep Learning để nhận dạng văn bản trong hình ảnh cảnh tự nhiên
Bài viết này đề cập đến nhận dạng ký tự quang học (OCR) để nhận dạng chữ cái hoặc văn bản trong hình ảnh cảnh tự nhiên. Chúng ta sẽ tìm hiểu về lý do tại sao nó là một vấn đề khó khăn, các cách tiếp cận được sử dụng để giải quyết và mã đi cùng với nó.

Chúng ta sống trong thời đại khi bất kỳ tổ chức hoặc công ty nào mở rộng quy mô và để phù hợp phải thay đổi cách họ nhìn vào công nghệ và thích nghi với sự thay đổi nhanh chóng của công nghệ. Chúng ta đã biết Google đã số hóa sách như thế nào hoặc cách Google Earth sử dụng NLP để xác định địa chỉ. Hoặc làm thế nào có thể đọc văn bản trong các tài liệu kỹ thuật số như hóa đơn, giấy tờ pháp lý, vv
Nhưng làm thế nào để nó hoạt động chính xác?
Bài viết này đề cập đến nhận dạng ký tự quang học (OCR) để nhận dạng văn bản trong hình ảnh cảnh tự nhiên. Chúng ta sẽ tìm hiểu về lý do tại sao nó là một vấn đề khó khăn, các cách tiếp cận được sử dụng để giải quyết và mã đi cùng với nó.
Tổng quan
Trong thời đại số hóa này, việc lưu trữ, chỉnh sửa, lập chỉ mục và tìm kiếm thông tin trong tài liệu kỹ thuật số dễ dàng hơn nhiều so với việc dành hàng giờ để cuộn qua các tài liệu được in / viết tay / đánh máy.
Và hơn nữa, việc tìm kiếm thứ gì đó trong một tài liệu phi kỹ thuật số lớn không chỉ tốn thời gian mà còn có khả năng chúng ta bỏ lỡ thông tin trong khi cuộn tài liệu theo cách thủ công. May mắn cho chúng ta, máy tính đang trở nên tốt hơn mỗi ngày khi thực hiện các nhiệm vụ mà con người nghĩ rằng chỉ mình mới có thể làm.
Trích xuất văn bản từ hình ảnh có nhiều ứng dụng.
Một số ứng dụng là nhận dạng hộ chiếu, nhận dạng biển số tự động, chuyển đổi văn bản viết tay thành văn bản kỹ thuật số, chuyển đổi văn bản đánh máy sang văn bản kỹ thuật số, v.v.
Thử thách

Nhiều triển khai OCR đã có sẵn ngay cả trước khi bùng nổ Deep Learning vào năm 2012. OCR vẫn là một vấn đề thách thức đặc biệt là khi hình ảnh văn bản được chụp trong môi trường không bị giới hạn. Khi hình ảnh chứa nền phức tạp, nhiễu, phông chữ khác nhau và biến dạng hình học trong hình ảnh.
Chính trong những tình huống như vậy công cụ OCR là biện pháp tốt nhất được sử dụng để nhận dạng văn bản
Ta có thể chia văn bản thành 2 loại:
- Văn bản có cấu trúc- Văn bản trong một tài liệu đánh máy. Trong một nền tảng tiêu chuẩn, có hàng lối, phông chữ tiêu chuẩn.

- Văn bản phi cấu trúc- Văn bản tại các vị trí ngẫu nhiên trong một khung cảnh tự nhiên. Văn bản thưa thớt, không có cấu trúc hàng thích hợp, nền phức tạp, tại vị trí ngẫu nhiên trong ảnh và không có phông chữ chuẩn.

Rất nhiều kỹ thuật trước đó đã giải quyết vấn đề OCR cho văn bản có cấu trúc.
Nhưng những kỹ thuật này đã không hoạt động đúng cho văn bản phi cấu trúc
Trong bài này, chúng ta sẽ tập trung nhiều hơn vào văn bản phi cấu trúc, đây là một vấn đề phức tạp hơn để giải quyết .
Như chúng ta biết trong thế giới Deep Learning, không có một giải pháp nào phù hợp với tất cả. Chúng ta sẽ thấy nhiều cách tiếp cận để giải quyết vấn đề và sẽ làm việc thông qua một cách tiếp cận trong số đó.
Bộ dữ liệu cho OCR với văn bản phi cấu trúc
Có rất nhiều bộ dữ liệu có sẵn bằng tiếng Anh nhưng việc tìm bộ dữ liệu cho các ngôn ngữ khác khó hơn. Các bộ dữ liệu khác nhau trình bày các nhiệm vụ khác nhau để được giải quyết. Dưới đây là một vài ví dụ về các bộ dữ liệu thường được sử dụng cho các OCR.
Tập dữ liệu SVHN
Bộ số liệu của Street View House chứa 73257 chữ số để đào tạo, 26032 chữ số để thử nghiệm và thêm 531131 dưới dạng dữ liệu đào tạo bổ sung. Bộ dữ liệu bao gồm 10 nhãn là các chữ số 0-9. Bộ dữ liệu khác với MNIST vì SVHN có hình ảnh số nhà với số nhà dựa trên các nền khác nhau. Bộ dữ liệu có các hộp giới hạn xung quanh mỗi chữ số thay vì có một vài hình ảnh của các chữ số như trong MNIST.
Tập dữ liệu cảnh
Bộ dữ liệu này bao gồm 3000 hình ảnh trong các hoàn cảnh khác nhau (trong nhà và ngoài trời) và điều kiện ánh sáng (bóng tối, ánh sáng và ban đêm), với văn bản bằng tiếng Hàn và tiếng Anh. Một số hình ảnh cũng chứa chữ số.
Tập dữ liệu Devanagri
Bộ dữ liệu này cung cấp cho chúng tôi 1800 mẫu từ 36 lớp ký tự được lấy bởi 25 nhà văn khác nhau trong tập devanagri.
Và có nhiều các ký tự Trung Quốc , CAPTCHA hoặc các từ viết tay .
Đọc văn bản trong môi trường tự nhiên
Bất kỳ hệ thống OCR nào cũng tuân theo các bước sau:

Image Preprocessing( Tiền sử lý)
- Loại bỏ nhiễu khỏi hình ảnh
- Xóa nền phức tạp khỏi hình ảnh
- Xử lý các điều kiện khác nhau trong ảnh

Đây là những cách tiêu chuẩn để xử lý hình ảnh trong tác vụ thị giác máy tính. Chúng tôi sẽ không tập trung vào bước tiền xử lý trong blog này.
Text Detection (Phát hiện văn bản )

Kỹ thuật phát hiện văn bản cần thiết để phát hiện văn bản trong hình ảnh, tạo và giới hạn hộp xung quanh phần hình ảnh có văn bản.
Kỹ thuật cửa sổ trượt
Hộp giới hạn có thể được tạo xung quanh văn bản thông qua kỹ thuật cửa sổ trượt. Trong kỹ thuật này, một cửa sổ trượt đi qua hình ảnh để phát hiện văn bản trong cửa sổ đó, giống như một mạng lưới thần kinh tích chập. Thử với kích thước cửa sổ khác nhau để không bỏ lỡ phần văn bản với kích thước khác nhau. Có một triển khai tích chập của cửa sổ trượt có thể làm giảm thời gian tính toán.
Dò đơn và dò theo vùng
Có các kỹ thuật phát hiện văn bản như YOLO (dò đơn) và các kỹ thuật phát hiện văn bản theo vùng để phát hiện văn bản trong ảnh.
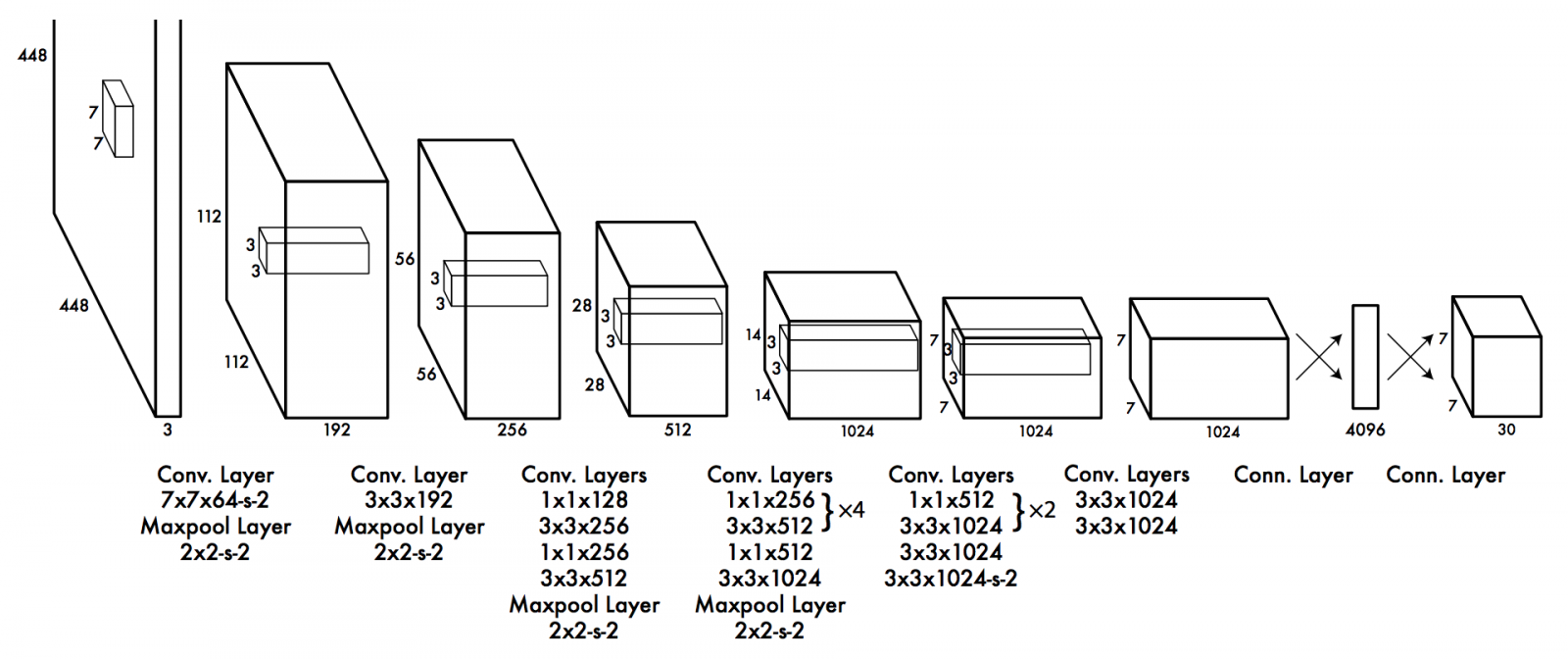
Kiến trúc YOLO
YOLO là các kỹ thuật chụp một lần khi bạn chỉ truyền hình ảnh một lần để phát hiện văn bản trong vùng đó, không giống như cửa sổ trượt.
Cách tiếp cận dựa trên khu vực được thực hiện trong hai bước.
- Đầu tiên, đề xuất khu vực có thể có văn bản
- Sau đó phân loại khu vực nếu nó có văn bản
EAST (Trình phát hiện văn bản trong cảnh chính xác hiệu quả)
Đây là một phương pháp Deep Learning rất mạnh mẽ để phát hiện văn bản dựa trên bài báo này . Nó có thể tìm thấy các hộp giới hạn ngang và xoay. Nó có thể được sử dụng kết hợp với bất kỳ phương pháp nhận dạng văn bản nào khác.
Hệ thống phát hiện văn bản trong bài viết này đã loại trừ các bước dư thừa và trung gian và chỉ có hai giai đoạn.
Người ta sử dụng mạng tích chập hoàn toàn để trực tiếp tạo dự đoán mức độ từ hoặc dòng văn bản. Các dự đoán được tạo ra có thể xoay hình chữ nhật hoặc hình tứ giác được xử lý thêm thông qua bước triệt tiêu để mang lại đầu ra cuối cùng.
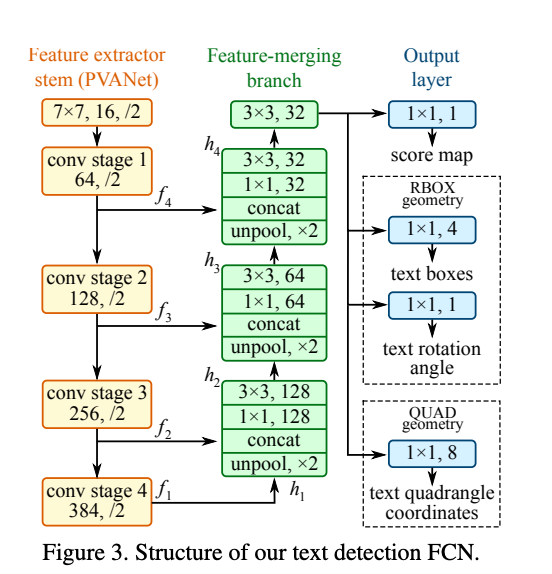
EAST có thể phát hiện văn bản cả trong hình ảnh và trong video, nó chạy gần thời gian thực ở mức 13FPS trên hình ảnh 720p với độ chính xác phát hiện văn bản cao. Một lợi ích khác của kỹ thuật này là việc triển khai nó có sẵn trong OpenCV 3.4.2 và OpenCV 4. Chúng ta sẽ thấy mô hình EAST này hoạt động cùng với nhận dạng văn bản.
Text Recognition ( Nhận dạng văn bản)
Khi chúng ta đã phát hiện các hộp giới hạn có văn bản, bước tiếp theo là nhận dạng văn bản. Có một số kỹ thuật để nhận dạng văn bản. Chúng ta sẽ thảo luận về một số kỹ thuật tốt nhất sau đây:
CRNN
Mạng thần kinh tái phát liên tục (CRNN) là sự kết hợp của mất CNN, RNN và CTC (Phân loại tạm thời kết nối) cho các tác vụ nhận dạng chuỗi dựa trên hình ảnh, như nhận dạng văn bản cảnh và OCR. Kiến trúc mạng đã được lấy từ bài báo này xuất bản năm 2015.
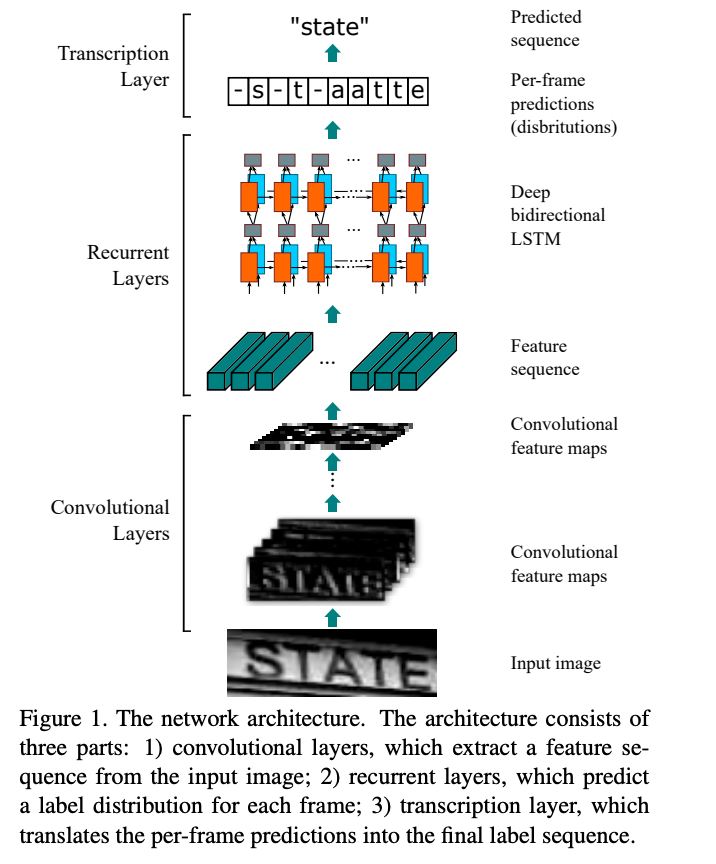
Kiến trúc mạng thần kinh này tích hợp tính năng trích xuất, mô hình hóa chuỗi và sao chép vào một khung thống nhất. Mô hình này không cần phân đoạn đối tượng.
Mạng thần kinh tích chập ( The convolution neural network) trích xuất các tính năng từ hình ảnh đầu vào (vùng phát hiện văn bản).
Mạng thần kinh tái phát hai chiều sâu ( The deep bidirectional recurrent neural network) dự đoán chuỗi ký tự với một số mối quan hệ giữa các ký tự.
Lớp phiên mã ( The transcription layer) chuyển đổi mỗi khung hình được tạo bởi RNN thành một chuỗi nhãn. Có hai chế độ phiên mã, đó là phiên mã không có từ vựng và phiên mã từ vựng dựa trên từ vựng.
Máy học OCR với Tesseract
Tesseract ban đầu được phát triển tại Phòng thí nghiệm Hewlett-Packard từ năm 1985 đến năm 1994. Năm 2005, nó được mở nguồn bởi HP. AS Theo wikipedia-
Năm 2006, Tesseract được coi là một trong những công cụ OCR mã nguồn mở chính xác nhất hiện có.
Khả năng của Tesseract chủ yếu giới hạn ở dữ liệu văn bản có cấu trúc. Nó sẽ thực hiện khá kém trong văn bản phi cấu trúc
Phương pháp dựa trên Deep Learning thực hiện tốt hơn cho dữ liệu phi cấu trúc. Tesseract 4 đã bổ sung khả năng deep learning với mạng LSTM (một loại công cụ OCR dựa trên mạng thần kinh tái phát) tập trung vào nhận dạng dòng nhưng cũng hỗ trợ công cụ Tesseract OCR kế thừa của Tesseract 3 hoạt động bằng cách nhận dạng các mẫu ký tự. Phiên bản ổn định mới nhất 4.1.0 được phát hành vào ngày 7 tháng 7 năm 2019. Phiên bản này chính xác hơn đáng kể trên văn bản phi cấu trúc.
Ở phần sau của bài biết, chúng ta sẽ đi vào ví dụ cụ thể áp dụng OCR để nhận dạng ký tự văn bản
Theo dõi VnCoder trên Facebook, để cập nhật những bài viết, tin tức và khoá học mới nhất!
Bài viết liên quan

Bài viết mới




Được xem nhiều nhất
[Computer Vision] làm quen với Object Detection (nhận diện vật thể) ch...
OCR dựa trên nền tảng Deep Learning để nhận dạng văn bản trong hình ản...
OCR dựa trên nền tảng Deep Learning để nhận dạng văn bản trong hình ản...
5 ý tưởng dự án machine Learning (học máy) cho người mới bắt đầu
Machine Learning cho người mới bắt đầu (Part 1)
Khóa học liên quan

AI - Machine Learning cơ bản
Lượt xem: 18976
Chuyên mục: Machine Learning