


















- Bài 1: Tổng quan AI
- Bài 2: Machine Learning
- Bài 3: Chuẩn bị dữ liệu
- Bài 4: Supervised Learning: Classification phần 1
- Bài 5: Supervised Learning: Classification phần 2
- Bài 6: Supervised Learning: Regression
- Bài 7: Logic Programming
- Bài 8: Unsupervised Learning: Clustering phần 1
- Bài 9: Unsupervised Learning: Clustering phần 2
- Bài 10: Natural Language Processing
- Bài 11: NLTK Package phần 1
- Bài 12: NLTK Package phần 2
- Bài 13: Analyzing Time Series Data phần 1
- Bài 14: Analyzing Time Series Data phần 2
- Bài 15: Nhận diện giọng nói phần 1
- Bài 16: Nhận diện giọng nói - phần 2
- Bài 17: Heuristic Search
- Bài 18: Gaming - Phần 1
- Bài 19: Gaming - Phần 2
- Bài 20: Neural Networks
- Bài 21: Reinforcement Learning
- Bài 22: Thuật toán di truyền
- Bài 23: Computer Vision
- Bài 24: Deep Learning
Bài 14: Analyzing Time Series Data phần 2 - Lập trình AI bằng Python
Đăng bởi: Admin | Lượt xem: 3448 | Chuyên mục: AI
5. Trích xuất thống kê từ Time Series Data :
a. Trung bình :
Sử dụng hàm mean() :
timeseries.mean()Kết quả như sau :
-0.11143128165238671b. Maximum :
Sử dụng hàm max :
timeseries.max()Kết quả :
3.4952999999999999c. Minimum :
Sử dụng hàm min():
timeseries.min()Kết quả :
-4.2656999999999998d. Tổng hợp :
Nếu bạn muốn tính toán tất cả các thống kê cùng một lúc, sử dụng hàm describe()
timeseries.describe()Kết quả như sau :
count 817.000000
mean -0.111431
std 1.003151
min -4.265700
25% -0.649430
50% -0.042744
75% 0.475720
max 3.495300
dtype: float64e. Re-sampling :
Bạn có thể lấy mẫu lại dữ liệu theo một tần suất thời gian khác. Hai tham số để thực hiện lấy mẫu lại là
- Time period
- Method
f. Re-sampling với mean()
Sử dụng hàm mean() để resample dữ liệu :
timeseries_mm = timeseries.resample("A").mean()
timeseries_mm.plot(style = 'g--')
plt.show()Sau đó, bạn có thể quan sát biểu đồ sau là đầu ra của việc lấy mẫu lại bằng cách sử dụng mean ()
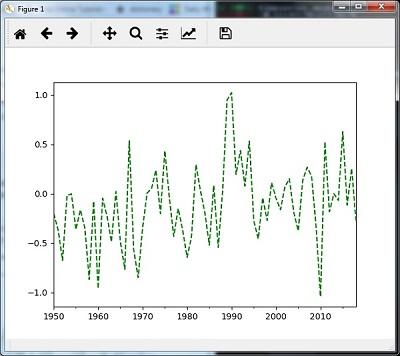
g. Re-sampling với median()
timeseries_mm = timeseries.resample("A").median()
timeseries_mm.plot()
plt.show()quan sát biểu đồ output :
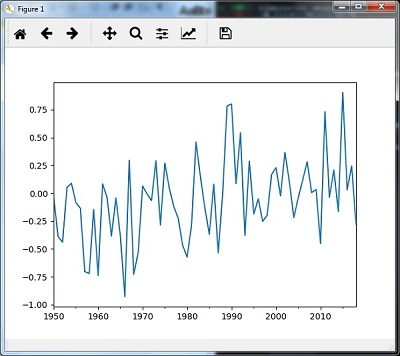
i. Rolling Mean
timeseries.rolling(window = 12, center = False).mean().plot(style = '-g')
plt.show()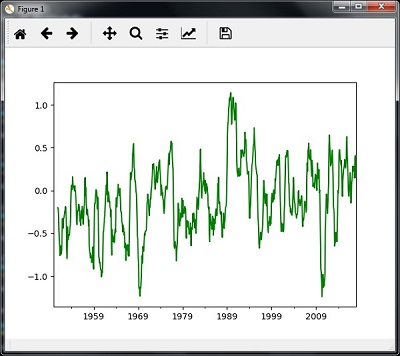
6. Phân tích dữ liệu tuần tự bằng mô hình Markov ẩn (HMM)
HMM là một mô hình thống kê được sử dụng rộng rãi cho dữ liệu có tính liên tục và khả năng mở rộng như phân tích thị trường chứng khoán theo chuỗi thời gian, kiểm tra sức khỏe và nhận dạng giọng nói. Phần này đề cập chi tiết đến việc phân tích dữ liệu tuần tự bằng Mô hình Markov ẩn (HMM).
a. Hidden Markov Model (HMM)
HMM là một mô hình ngẫu nhiên được xây dựng dựa trên khái niệm chuỗi Markov dựa trên giả định rằng xác suất của các thống kê trong tương lai chỉ phụ thuộc vào trạng thái quy trình hiện tại thay vì bất kỳ trạng thái nào trước đó. Ví dụ, khi tung một đồng xu, chúng ta không thể nói rằng kết quả của lần tung thứ năm sẽ là mặt sấp. Điều này là do một đồng xu không có bất kỳ bộ nhớ nào và kết quả tiếp theo không phụ thuộc vào kết quả trước đó.
Về mặt toán học, HMM bao gồm các biến sau:
States(S) :
Là một tập hợp các trạng thái ẩn hoặc tiềm ẩn trong HMM. Nó được ký hiệu là S.
Output symbols (O) :
Là một tập hợp các ký hiệu đầu ra có thể có trong HMM. Nó được ký hiệu là O.
Ma trận xác suất chuyển trạng thái (A) :
Nó là xác suất thực hiện chuyển đổi từ trạng thái này sang từng trạng thái khác. Nó được ký hiệu là A.
Ma trận xác suất phát thải quan sát (B) :
Là xác suất emitting/observing một kí hiệu ở một trạng thái cụ thể. Nó được ký hiệu là B.
7. Ví dụ :
Trong ví dụ này, chúng ta sẽ phân tích từng bước dữ liệu của thị trường chứng khoán, để có được ý tưởng về cách HMM hoạt động với dữ liệu tuần tự hoặc chuỗi thời gian. Xin lưu ý rằng chúng tôi đang triển khai ví dụ này bằng Python.
Sử dụng package matpotlib.finance :
import numpy as np
from matplotlib import cm, pyplot as plt
from matplotlib.dates import YearLocator, MonthLocator
try:
from matplotlib.finance import quotes_historical_yahoo_och1
except ImportError:
from matplotlib.finance import (
quotes_historical_yahoo as quotes_historical_yahoo_och1)
from hmmlearn.hmm import GaussianHMMLoad dữ liệu từ start date và end date :
start_date = datetime.date(1995, 10, 10)
end_date = datetime.date(2015, 4, 25)
quotes = quotes_historical_yahoo_och1('INTC', start_date, end_date)Trong bước này, ta sẽ trích xuất các báo giá kết thúc mỗi ngày. Đối với điều này, hãy sử dụng lệnh sau:
closing_quotes = np.array([quote[2] for quote in quotes])Bây giờ, tôi sẽ trích xuất khối lượng cổ phiếu được giao dịch mỗi ngày. Đối với điều này, hãy sử dụng lệnh sau:
volumes = np.array([quote[5] for quote in quotes])[1:]Tại đây, lấy phần trăm chênh lệch của giá cổ phiếu đóng cửa, sử dụng đoạn code sau :
diff_percentages = 100.0 * np.diff(closing_quotes) / closing_quotes[:-]
dates = np.array([quote[0] for quote in quotes], dtype = np.int)[1:]
training_data = np.column_stack([diff_percentages, volumes])Khởi tạo và huấn luyện Gaussian HMM
hmm = GaussianHMM(n_components = 7, covariance_type = 'diag', n_iter = 1000)
with warnings.catch_warnings():
warnings.simplefilter('ignore')
hmm.fit(training_data)Tạo dữ liệu sử dụng mô hình HMM, sử dụng đoạn lệnh sau :
num_samples = 300
samples, _ = hmm.sample(num_samples)Cuối cùng, trong bước này,mình vẽ và hình dung phần trăm chênh lệch và khối lượng cổ phiếu được giao dịch dưới dạng sản lượng dưới dạng đồ thị.
Sử dụng đoạn code sau để vẽ và hình dung tỷ lệ phần trăm chênh lệch
plt.figure()
plt.title('Difference percentages')
plt.plot(np.arange(num_samples), samples[:, 0], c = 'black')Vẽ và hiển thị giá cổ phiếu
plt.figure()
plt.title('Volume of shares')
plt.plot(np.arange(num_samples), samples[:, 1], c = 'black')
plt.ylim(ymin = 0)
plt.show()Theo dõi VnCoder trên Facebook, để cập nhật những bài viết, tin tức và khoá học mới nhất!
- Bài 1: Tổng quan AI
- Bài 2: Machine Learning
- Bài 3: Chuẩn bị dữ liệu
- Bài 4: Supervised Learning: Classification phần 1
- Bài 5: Supervised Learning: Classification phần 2
- Bài 6: Supervised Learning: Regression
- Bài 7: Logic Programming
- Bài 8: Unsupervised Learning: Clustering phần 1
- Bài 9: Unsupervised Learning: Clustering phần 2
- Bài 10: Natural Language Processing
- Bài 11: NLTK Package phần 1
- Bài 12: NLTK Package phần 2
- Bài 13: Analyzing Time Series Data phần 1
- Bài 14: Analyzing Time Series Data phần 2
- Bài 15: Nhận diện giọng nói phần 1
- Bài 16: Nhận diện giọng nói - phần 2
- Bài 17: Heuristic Search
- Bài 18: Gaming - Phần 1
- Bài 19: Gaming - Phần 2
- Bài 20: Neural Networks
- Bài 21: Reinforcement Learning
- Bài 22: Thuật toán di truyền
- Bài 23: Computer Vision
- Bài 24: Deep Learning