


















- Bài 1: Giới thiệu
- Bài 2: Cài đặt
- Bài 3: Cấu hình backend
- Bài 4: Tổng quan về Deep learning
- Bài 5: Deep learning
- Bài 6: Mô đun
- Bài 7: Layers (phần 1)
- Bài 8: Layers (Phần 2)
- Bài 9: Tuỳ chỉnh Layer
- Bài 10: Models
- Bài 11: Tổng hợp Model (Phần 1)
- Bài 12: Tổng hợp Model (Phần 2)
- Bài 13: Đánh giá và dự đoán mô hình
- Bài 14: Convolution Neural Network
- Bài 15: Dự đoán hồi quy sử dụng MPL
- Bài 16: Dự đoán chuỗi thời gian bằng LSTM RNN
- Bài 17: Ứng dụng
- Bài 18: Dự đoán thời gian thực với mô hình ResNet
- Bài 19: Pre-Trained Models
Bài 14: Convolution Neural Network - Keras cơ bản
Đăng bởi: Admin | Lượt xem: 4175 | Chuyên mục: AI
Ta tiến hành sửa đổi mô hình từ MPL thành Mạng thần kinh Convolution (CNN) trong bài toán nhận dạng chữ số trước đó
CNN có thể được trình bày như sau:
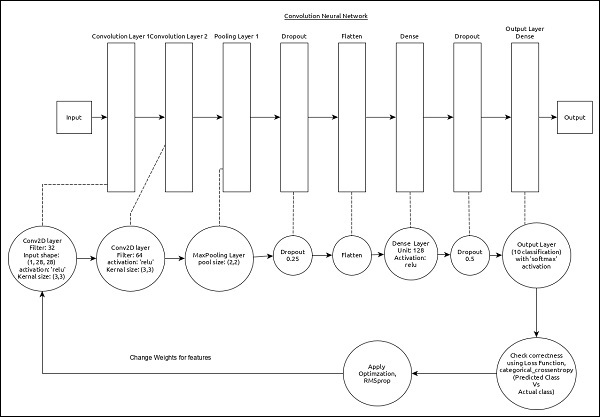
Các tính năng cốt lõi của mô hình như sau:
- Lớp đầu vào bao gồm (1, 8, 28) giá trị.
- Lớp đầu tiên, Conv2D bao gồm 32 bộ lọc và chức năng kích hoạt ‘relu’ với kích thước hạt nhân, (3,3).
- Lớp thứ hai, Conv2D bao gồm 64 bộ lọc và chức năng kích hoạt ‘relu’ với kích thước hạt nhân, (3,3).
- Lớp Thrid, MaxPooling có kích thước nhóm là (2, 2).
- Lớp thứ năm, Flatten được sử dụng để làm phẳng tất cả đầu vào của nó thành một chiều duy nhất.
- Lớp thứ sáu, Dense bao gồm 128 tế bào thần kinh và chức năng kích hoạt ‘relu’.
- Lớp thứ bảy, Dropout có giá trị là 0,5.
- Lớp thứ tám và lớp cuối cùng bao gồm 10 tế bào thần kinh và chức năng kích hoạt ‘softmax’.
- Sử dụng categorical_crossentropy làm hàm mất mát.
- Sử dụng Adadelta () làm Trình tối ưu hóa.
- Sử dụng độ chính xác làm thước đo.
- Sử dụng 128 batch size.
- epochs là 20
Bước 1 − Import các thư viện cần thiết
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K
import numpy as npBước 2 − Load dữ liệu
Import mnist dataset
(x_train, y_train), (x_test, y_test) = mnist.load_data()Bước 3 − Xử lý dữ liệu
Ta thay đổi tập dữ liệu theo mô hình để nó có thể được đưa vào mô hình.
img_rows, img_cols = 28, 28
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)Việc xử lý dữ liệu tương tự như mô hình MPL ngoại trừ hình dạng của dữ liệu đầu vào và cấu hình định dạng hình ảnh.
Bước 4 − Tạo mô hình
Tiến hành tạo ra mô hình thực tế.
model = Sequential()
model.add(Conv2D(32, kernel_size = (3, 3),
activation = 'relu', input_shape = input_shape))
model.add(Conv2D(64, (3, 3), activation = 'relu'))
model.add(MaxPooling2D(pool_size = (2, 2)))
model.add(Dropout(0.25)) model.add(Flatten())
model.add(Dense(128, activation = 'relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation = 'softmax'))Bước 5 − Biên dịch mô hình
Biên dịch mô hình bằng cách sử dụng hàm mất mát, trình tối ưu hóa và số liệu đã chọn.
model.compile(loss = keras.losses.categorical_crossentropy,
optimizer = keras.optimizers.Adadelta(), metrics = ['accuracy'])Bước 6 − Huấn luyện mô hình
model.fit(
x_train, y_train,
batch_size = 128,
epochs = 12,
verbose = 1,
validation_data = (x_test, y_test)
)Kết quả trả về như sau :
Train on 60000 samples, validate on 10000 samples Epoch 1/12
60000/60000 [==============================] - 84s 1ms/step - loss: 0.2687
- acc: 0.9173 - val_loss: 0.0549 - val_acc: 0.9827 Epoch 2/12
60000/60000 [==============================] - 86s 1ms/step - loss: 0.0899
- acc: 0.9737 - val_loss: 0.0452 - val_acc: 0.9845 Epoch 3/12
60000/60000 [==============================] - 83s 1ms/step - loss: 0.0666
- acc: 0.9804 - val_loss: 0.0362 - val_acc: 0.9879 Epoch 4/12
60000/60000 [==============================] - 81s 1ms/step - loss: 0.0564
- acc: 0.9830 - val_loss: 0.0336 - val_acc: 0.9890 Epoch 5/12
60000/60000 [==============================] - 86s 1ms/step - loss: 0.0472
- acc: 0.9861 - val_loss: 0.0312 - val_acc: 0.9901 Epoch 6/12
60000/60000 [==============================] - 83s 1ms/step - loss: 0.0414
- acc: 0.9877 - val_loss: 0.0306 - val_acc: 0.9902 Epoch 7/12
60000/60000 [==============================] - 89s 1ms/step - loss: 0.0375
-acc: 0.9883 - val_loss: 0.0281 - val_acc: 0.9906 Epoch 8/12
60000/60000 [==============================] - 91s 2ms/step - loss: 0.0339
- acc: 0.9893 - val_loss: 0.0280 - val_acc: 0.9912 Epoch 9/12
60000/60000 [==============================] - 89s 1ms/step - loss: 0.0325
- acc: 0.9901 - val_loss: 0.0260 - val_acc: 0.9909 Epoch 10/12
60000/60000 [==============================] - 89s 1ms/step - loss: 0.0284
- acc: 0.9910 - val_loss: 0.0250 - val_acc: 0.9919 Epoch 11/12
60000/60000 [==============================] - 86s 1ms/step - loss: 0.0287
- acc: 0.9907 - val_loss: 0.0264 - val_acc: 0.9916 Epoch 12/12
60000/60000 [==============================] - 86s 1ms/step - loss: 0.0265
- acc: 0.9920 - val_loss: 0.0249 - val_acc: 0.9922Bước 7 − Đánh giá mô hình
score = model.evaluate(x_test, y_test, verbose = 0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])Thực thi đoạn code trên sẽ xuất ra thông tin như sau:
Test loss: 0.024936060590433316
Test accuracy: 0.9922Độ chính xác là 99,22%. Đây là mô hình tốt nhất để xác định các chữ số viết tay.
Bước 8 − Dự đoán
Cuối cùng là dự đoán chữ viết tay từ ảnh
pred = model.predict(x_test)
pred = np.argmax(pred, axis = 1)[:5]
label = np.argmax(y_test,axis = 1)[:5]
print(pred)
print(label)Kết quả trả về như sau :
[7 2 1 0 4]
[7 2 1 0 4]Đầu ra của cả hai mảng là giống hệt nhau, cho biết mô hình dự đoán chính xác năm hình ảnh đầu tiên.
Theo dõi VnCoder trên Facebook, để cập nhật những bài viết, tin tức và khoá học mới nhất!
- Bài 1: Giới thiệu
- Bài 2: Cài đặt
- Bài 3: Cấu hình backend
- Bài 4: Tổng quan về Deep learning
- Bài 5: Deep learning
- Bài 6: Mô đun
- Bài 7: Layers (phần 1)
- Bài 8: Layers (Phần 2)
- Bài 9: Tuỳ chỉnh Layer
- Bài 10: Models
- Bài 11: Tổng hợp Model (Phần 1)
- Bài 12: Tổng hợp Model (Phần 2)
- Bài 13: Đánh giá và dự đoán mô hình
- Bài 14: Convolution Neural Network
- Bài 15: Dự đoán hồi quy sử dụng MPL
- Bài 16: Dự đoán chuỗi thời gian bằng LSTM RNN
- Bài 17: Ứng dụng
- Bài 18: Dự đoán thời gian thực với mô hình ResNet
- Bài 19: Pre-Trained Models