


















- Bài 1: Giới thiệu
- Bài 2: Cài đặt
- Bài 3: Cấu hình backend
- Bài 4: Tổng quan về Deep learning
- Bài 5: Deep learning
- Bài 6: Mô đun
- Bài 7: Layers (phần 1)
- Bài 8: Layers (Phần 2)
- Bài 9: Tuỳ chỉnh Layer
- Bài 10: Models
- Bài 11: Tổng hợp Model (Phần 1)
- Bài 12: Tổng hợp Model (Phần 2)
- Bài 13: Đánh giá và dự đoán mô hình
- Bài 14: Convolution Neural Network
- Bài 15: Dự đoán hồi quy sử dụng MPL
- Bài 16: Dự đoán chuỗi thời gian bằng LSTM RNN
- Bài 17: Ứng dụng
- Bài 18: Dự đoán thời gian thực với mô hình ResNet
- Bài 19: Pre-Trained Models
Bài 16: Dự đoán chuỗi thời gian bằng LSTM RNN - Keras cơ bản
Đăng bởi: Admin | Lượt xem: 4866 | Chuyên mục: AI
Trong bài này, ta tiến hành viết một RNN đơn giản dựa trên bộ nhớ dài hạn (LSTM) để phân tích trình tự. Chuỗi là một tập hợp các giá trị trong đó mỗi giá trị tương ứng với một phiên bản thời gian cụ thể. Chúng ta hãy xem xét một ví dụ đơn giản về việc đọc một câu. Đọc và hiểu một câu bao gồm việc đọc từ theo thứ tự đã cho và cố gắng hiểu từng từ và nghĩa của nó trong ngữ cảnh nhất định và cuối cùng là hiểu câu đó theo cảm xúc tích cực hoặc tiêu cực.
Ở đây, các từ được coi là giá trị và giá trị đầu tiên tương ứng với từ đầu tiên, giá trị thứ hai tương ứng với từ thứ hai, v.v. và thứ tự sẽ được duy trì nghiêm ngặt. Phân tích trình tự được sử dụng thường xuyên trong xử lý ngôn ngữ tự nhiên để tìm ra phân tích tình cảm của văn bản đã cho.
Ta sẽ thử tạo một mô hình LSTM để phân tích các đánh giá phim IMDB và tìm ra cảm xúc tích cực / tiêu cực của nó.
Mô hình phân tích trình tự có thể được trình bày như sau:
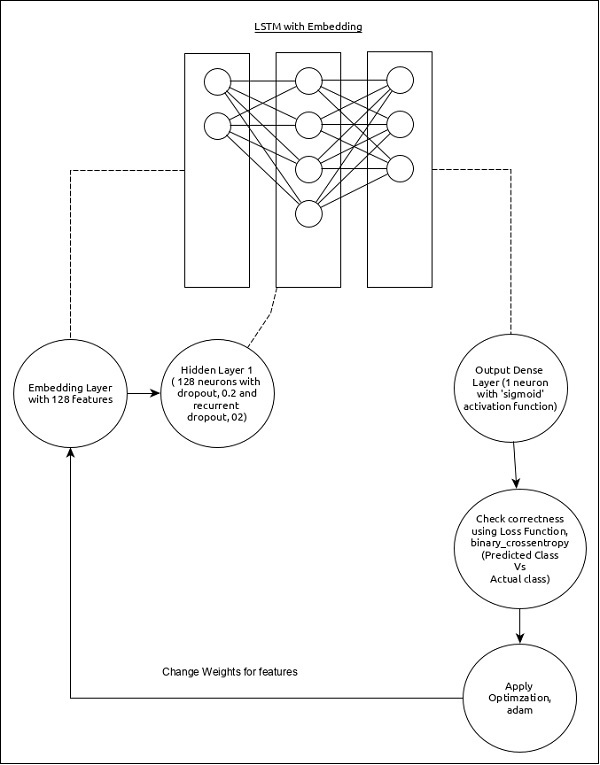
Các tính năng cốt lõi của mô hình như sau:
- Lớp đầu vào sử dụng lớp Embedding(Nhúng) với 128 đặc trưng (features).
- Lớp đầu tiên, Dense bao gồm 128 đơn vị với số normal dropout và số recurrent dropout liên tục được đặt thành 0,2.
- Lớp đầu ra, Dense bao gồm 1 đơn vị và hàm kích hoạt (activation) ‘sigmoid’.
- Sử dụng binary_crossentropy làm hàm mất mát.
- Sử dụng adam làm Trình tối ưu hóa.
- Sử dụng accuracy (độ chính xác ) làm thước đo.
- Sử dụng 32 batch size.
- 15 epochs.
- Độ dài tối đa của từ là 80
- Một câu tối đa 2000 từ
Bước 1: Import các thư viện cần thiết :
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense, Embedding
from keras.layers import LSTM
from keras.datasets import imdbBước 2: Load dữ liệu
import imdb dataset.
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words = 2000)Trong đó
- imdb là một tập dữ liệu do Keras cung cấp. Đại diện cho một bộ sưu tập các bộ phim và các đánh giá .
- num_words số lượng từ tối đa trong bài đánh giá.
Bước 3: Xử lý dữ liệu
Thay đổi tập dữ liệu theo mô hình để nó có thể được đưa vào mô hình . Dữ liệu có thể được thay đổi bằng cách dưới đây:
x_train = sequence.pad_sequences(x_train, maxlen=80)
x_test = sequence.pad_sequences(x_test, maxlen=80)Trong đó :
sequence.pad_sequences chuyển đổi danh sách dữ liệu đầu vào có hình dạng, (dữ liệu) thành mảng NumPy 2D có hình dạng (data, timesteps). Về cơ bản, nó thêm khái niệm bước thời gian vào dữ liệu đã cho. Nó tạo ra các timesteps dài, maxlen.
Bước 4: Tạo mô hình
Tạo mô hình thực tiễn
model = Sequential()
model.add(Embedding(2000, 128))
model.add(LSTM(128, dropout = 0.2, recurrent_dropout = 0.2))
model.add(Dense(1, activation = 'sigmoid'))Trong đó:
Sử dụng lớp Embedding làm lớp đầu vào và sau đó thêm lớp LSTM. Cuối cùng, một lớp Dense được sử dụng làm lớp đầu ra.
Bước 5: Biên dịch mô hình
Sử dụng hàm mất mát, trình tối ưu hóa và số liệu đã chọn.
model.compile(loss = 'binary_crossentropy',
optimizer = 'adam', metrics = ['accuracy'])Bước 6: Huấn luyện mô hình
Sử dụng phương thức fit()
model.fit(
x_train, y_train,
batch_size = 32,
epochs = 15,
validation_data = (x_test, y_test)
)Sau khi thực thi , kết quả hiện trên màn hình như sau :
Epoch 1/15 2019-09-24 01:19:01.151247: I
tensorflow/core/platform/cpu_feature_guard.cc:142]
Your CPU supports instructions that this
TensorFlow binary was not co mpiled to use: AVX2
25000/25000 [==============================] - 101s 4ms/step - loss: 0.4707
- acc: 0.7716 - val_loss: 0.3769 - val_acc: 0.8349 Epoch 2/15
25000/25000 [==============================] - 95s 4ms/step - loss: 0.3058
- acc: 0.8756 - val_loss: 0.3763 - val_acc: 0.8350 Epoch 3/15
25000/25000 [==============================] - 91s 4ms/step - loss: 0.2100
- acc: 0.9178 - val_loss: 0.5065 - val_acc: 0.8110 Epoch 4/15
25000/25000 [==============================] - 90s 4ms/step - loss: 0.1394
- acc: 0.9495 - val_loss: 0.6046 - val_acc: 0.8146 Epoch 5/15
25000/25000 [==============================] - 90s 4ms/step - loss: 0.0973
- acc: 0.9652 - val_loss: 0.5969 - val_acc: 0.8147 Epoch 6/15
25000/25000 [==============================] - 98s 4ms/step - loss: 0.0759
- acc: 0.9730 - val_loss: 0.6368 - val_acc: 0.8208 Epoch 7/15
25000/25000 [==============================] - 95s 4ms/step - loss: 0.0578
- acc: 0.9811 - val_loss: 0.6657 - val_acc: 0.8184 Epoch 8/15
25000/25000 [==============================] - 97s 4ms/step - loss: 0.0448
- acc: 0.9850 - val_loss: 0.7452 - val_acc: 0.8136 Epoch 9/15
25000/25000 [==============================] - 95s 4ms/step - loss: 0.0324
- acc: 0.9894 - val_loss: 0.7616 - val_acc: 0.8162Epoch 10/15
25000/25000 [==============================] - 100s 4ms/step - loss: 0.0247
- acc: 0.9922 - val_loss: 0.9654 - val_acc: 0.8148 Epoch 11/15
25000/25000 [==============================] - 99s 4ms/step - loss: 0.0169
- acc: 0.9946 - val_loss: 1.0013 - val_acc: 0.8104 Epoch 12/15
25000/25000 [==============================] - 90s 4ms/step - loss: 0.0154
- acc: 0.9948 - val_loss: 1.0316 - val_acc: 0.8100 Epoch 13/15
25000/25000 [==============================] - 89s 4ms/step - loss: 0.0113
- acc: 0.9963 - val_loss: 1.1138 - val_acc: 0.8108 Epoch 14/15
25000/25000 [==============================] - 89s 4ms/step - loss: 0.0106
- acc: 0.9971 - val_loss: 1.0538 - val_acc: 0.8102 Epoch 15/15
25000/25000 [==============================] - 89s 4ms/step - loss: 0.0090
- acc: 0.9972 - val_loss: 1.1453 - val_acc: 0.8129
25000/25000 [==============================] - 10s 390us/stepBước 7 − Đánh giá mô hình
Sử dụng dữ liệu test để đánh giá dữ liệu
score, acc = model.evaluate(x_test, y_test, batch_size = 32)
print('Test score:', score)
print('Test accuracy:', acc)Kết quả:
Test score: 1.145306069601178
Test accuracy: 0.81292Theo dõi VnCoder trên Facebook, để cập nhật những bài viết, tin tức và khoá học mới nhất!
- Bài 1: Giới thiệu
- Bài 2: Cài đặt
- Bài 3: Cấu hình backend
- Bài 4: Tổng quan về Deep learning
- Bài 5: Deep learning
- Bài 6: Mô đun
- Bài 7: Layers (phần 1)
- Bài 8: Layers (Phần 2)
- Bài 9: Tuỳ chỉnh Layer
- Bài 10: Models
- Bài 11: Tổng hợp Model (Phần 1)
- Bài 12: Tổng hợp Model (Phần 2)
- Bài 13: Đánh giá và dự đoán mô hình
- Bài 14: Convolution Neural Network
- Bài 15: Dự đoán hồi quy sử dụng MPL
- Bài 16: Dự đoán chuỗi thời gian bằng LSTM RNN
- Bài 17: Ứng dụng
- Bài 18: Dự đoán thời gian thực với mô hình ResNet
- Bài 19: Pre-Trained Models