


















- Bài 1: Giới thiệu
- Bài 2: Thiết lập project
- Bài 3: Lấy dữ liệu
- Bài 4: Tái cấu trúc dữ liệu
- Bài 5: Chuẩn bị dữ liệu
- Bài 6: Split dữ liệu
- Bài 7: Xây dựng bài toán phân loại
- Bài 8: Hạn chế và Tổng kết
Bài 3: Lấy dữ liệu - Hồi quy Logistic - Python
Đăng bởi: Admin | Lượt xem: 2968 | Chuyên mục: AI
Các bước liên quan đến việc lấy dữ liệu để thực hiện hồi quy logistic trong Python được thảo luận chi tiết trong bài này.
1. Tải Dataset
Nếu bạn chưa tải xuống bộ dữ liệu UCI được đề cập trong bài trước, hãy tải xuống ngay ở đây. Bấm vào Thư mục Dữ liệu. Bạn sẽ thấy màn hình sau:

Tải xuống tệp bank.zip bằng cách nhấp vào liên kết đã cho. Tệp zip chứa các tệp sau

Ta sẽ sử dụng tệp bank.csv để phát triển mô hình của mình. Tệp bank-names.txt chứa mô tả về cơ sở dữ liệu mà bạn sẽ cần sau này. Bank-full.csv chứa tập dữ liệu lớn hơn nhiều mà bạn có thể sử dụng cho các phát triển nâng cao hơn.
Ở đây chúng tôi đã bao gồm tệp bank.csv trong zip nguồn có thể tải xuống. Tệp này chứa các trường được phân tách bằng dấu phẩy. Mình cũng đã thực hiện một số sửa đổi trong tệp. Bạn nên sử dụng tệp có trong zip nguồn dự án để phục vụ cho việc học của mình.
2. Loading dữ liệu
Để tải dữ liệu từ tệp csv mà bạn vừa sao chép, hãy nhập câu lệnh sau và chạy code.
In [2]: df = pd.read_csv('bank.csv', header=0)Bạn cũng sẽ có thể kiểm tra dữ liệu đã tải bằng cách chạy câu lệnh sau
IN [3]: df.head()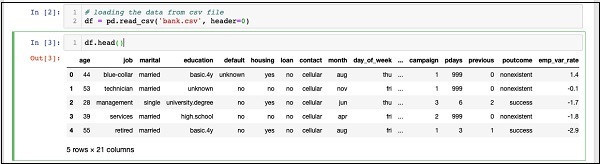
Về cơ bản, nó đã in năm hàng đầu tiên của dữ liệu được tải. Kiểm tra 21 cột hiện có. Ta sẽ chỉ sử dụng một số cột từ những cột này để phát triển mô hình.
Tiếp theo, chúng ta cần làm sạch dữ liệu. Dữ liệu có thể chứa một số hàng có NaN. Để loại bỏ các hàng như vậy, hãy sử dụng lệnh sau:
IN [4]: df = df.dropna()May mắn, bank.csv không chứa bất kỳ hàng nào có NaN, vì vậy bước này không thực sự bắt buộc trong trường hợp của ta. Tuy nhiên, nói chung rất khó để phát hiện ra các hàng như vậy trong một cơ sở dữ liệu khổng lồ. Vì vậy, luôn an toàn hơn khi chạy câu lệnh trên để làm sạch dữ liệu.
Lưu ý - Bạn có thể dễ dàng kiểm tra kích thước dữ liệu tại bất kỳ thời điểm nào bằng cách sử dụng câu lệnh sau:
IN [5]: print (df.shape)
(41188, 21)Số hàng và cột sẽ được in trong đầu ra như thể hiện ở dòng thứ hai ở trên.
Điều tiếp theo cần làm là kiểm tra sự phù hợp của từng cột đối với mô hình mà ta đang cố gắng xây dựng.
Theo dõi VnCoder trên Facebook, để cập nhật những bài viết, tin tức và khoá học mới nhất!