


















- Bài 1: Giới thiệu
- Bài 2: Thiết lập project
- Bài 3: Lấy dữ liệu
- Bài 4: Tái cấu trúc dữ liệu
- Bài 5: Chuẩn bị dữ liệu
- Bài 6: Split dữ liệu
- Bài 7: Xây dựng bài toán phân loại
- Bài 8: Hạn chế và Tổng kết
Bài 6: Split dữ liệu - Hồi quy Logistic - Python
Đăng bởi: Admin | Lượt xem: 2582 | Chuyên mục: AI
Ta có khoảng bốn mươi mốt bản ghi lẻ. Nếu sử dụng toàn bộ dữ liệu để xây dựng mô hình, sẽ không còn lại bất kỳ dữ liệu nào để thử nghiệm. Vì vậy, nói chung, ta chia toàn bộ tập dữ liệu thành hai phần, giả sử 70/30 phần trăm. Sử dụng 70% dữ liệu để xây dựng mô hình và phần còn lại để kiểm tra độ chính xác trong dự đoán của mô hình đã tạo . Bạn có thể sử dụng một tỷ lệ tách khác theo yêu cầu.
1. Tạo mảng đặc trưng :
Trước khi chia dữ liệu, ta tách dữ liệu thành hai mảng X và Y. Mảng X chứa tất cả các tính năng (cột dữ liệu) mà ta muốn phân tích và mảng Y là mảng một chiều gồm các giá trị boolean là đầu ra của Dự đoán.
Đầu tiên, thực thi câu lệnh Python sau để tạo mảng X:
In [17]: X = data.iloc[:,1:]Để kiểm tra nội dung của X, sử dụng head để in một vài bản ghi ban đầu. Mảng X như sau :
In [18]: X.head ()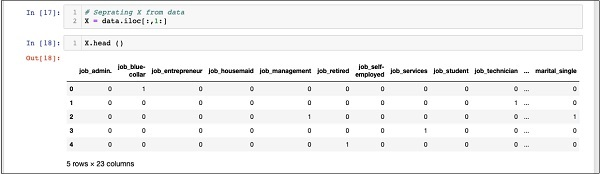
Mảng có một số hàng và 23 cột.
Tiếp theo, ta sẽ tạo mảng đầu ra chứa các giá trị “y”.
2. Tạo mảng đầu ra :
Để tạo một mảng cho cột giá trị dự đoán, hãy sử dụng câu lệnh Python sau:
In [19]: Y = data.iloc[:,0]Kiểm tra nội dung bằng head(). Kết quả như sau :
In [20]: Y.head()
Out[20]: 0 0
1 0
2 1
3 0
4 1
Name: y, dtype: int64Bây giờ, chia nhỏ dữ liệu bằng lệnh sau:
In [21]: X_train, X_test, Y_train, Y_test = train_test_split(X, Y, random_state=0)Bốn mảng được tạo ra gọi là X_train, Y_train, X_test và Y_test. Như trước, bạn có thể kiểm tra nội dung của các mảng này bằng cách sử dụng lệnh head. Ta sử dụng các mảng X_train và Y_train để đào tạo mô hình và các mảng X_test , Y_test để kiểm tra và xác thực.
Bây giờ, ta tiến hành xây dựng bộ phân loại
Theo dõi VnCoder trên Facebook, để cập nhật những bài viết, tin tức và khoá học mới nhất!