


















- Bài 1: Giới thiệu về Machine Learning
- Bài 2: Machine Learning - AI ngày nay có thể làm gì?
- Bài 3: Machine Learning - AI truyền thống
- Bài 4: Machine Learning - Machine Learning là gì?
- Bài 5: Machine Learning - Phân loại
- Bài 6: Machine Learning - Phân loại (p2)
- Bài 7: Machine Learning - Supervised Learning
- Bài 8: Machine Learning - Thư viện Scikit learn
- Bài 9: Machine Learning - Unsupervised learning
- Bài 10: Machine Learning - Artificial Neural Networks
- Bài 11: Machine Learning - Deep Learning
- Bài 12: Machine Learning - Skills
- Bài 13: Machine Learning - Implementing
- Bài 14: Khởi đầu với neural network
- Bài 15: Xử lý ảnh sử dụng Neural Network
- Bài 16: Mạng neuron tích chập
- Bài 17: Machine Learning - Kết luận
- Bài 18: Rút gọn : Phần 1
- Bài 19: Rút gọn - phần 2
- Bài 20: Rút gọn - phần 3
Bài 20: Rút gọn - phần 3 - AI - Machine Learning cơ bản
Đăng bởi: Admin | Lượt xem: 2274 | Chuyên mục: Machine Learning
Bài 12: Machine Learning - Skills - AI - Machine Learning cơ bản
Học máy có rất rộng và lớn , yêu cầu các kỹ năng trên một số lĩnh vực. Các kỹ năng bạn cần có để trở thành chuyên gia trong Học máy được liệt kê bên dưới:
- Số liệu thống kê
- Lý thuyết xác suất
- Giải tích
- Kỹ thuật tối ưu hóa
- Visualization
1. Sự cần thiết toán học trong Machine Learning:
Để cung cấp cho bạn một ý tưởng ngắn gọn về những kỹ năng bạn cần có được, hãy để chúng tôi thảo luận về một số ví dụ -Ký hiệu toán họcHầu hết các thuật toán học máy chủ yếu dựa trên toán học. Trình độ toán học mà bạn cần biết có lẽ chỉ là trình độ sơ cấp. Điều quan trọng là bạn phải có thể đọc ký hiệu mà các nhà toán học sử dụng trong các phương trình của họ. Ví dụ - nếu bạn có thể đọc ký hiệu và hiểu ý nghĩa của nó, bạn đã sẵn sàng cho việc học máy học. Nếu không, bạn có thể cần phải học lại kiến thức toán học của mình.
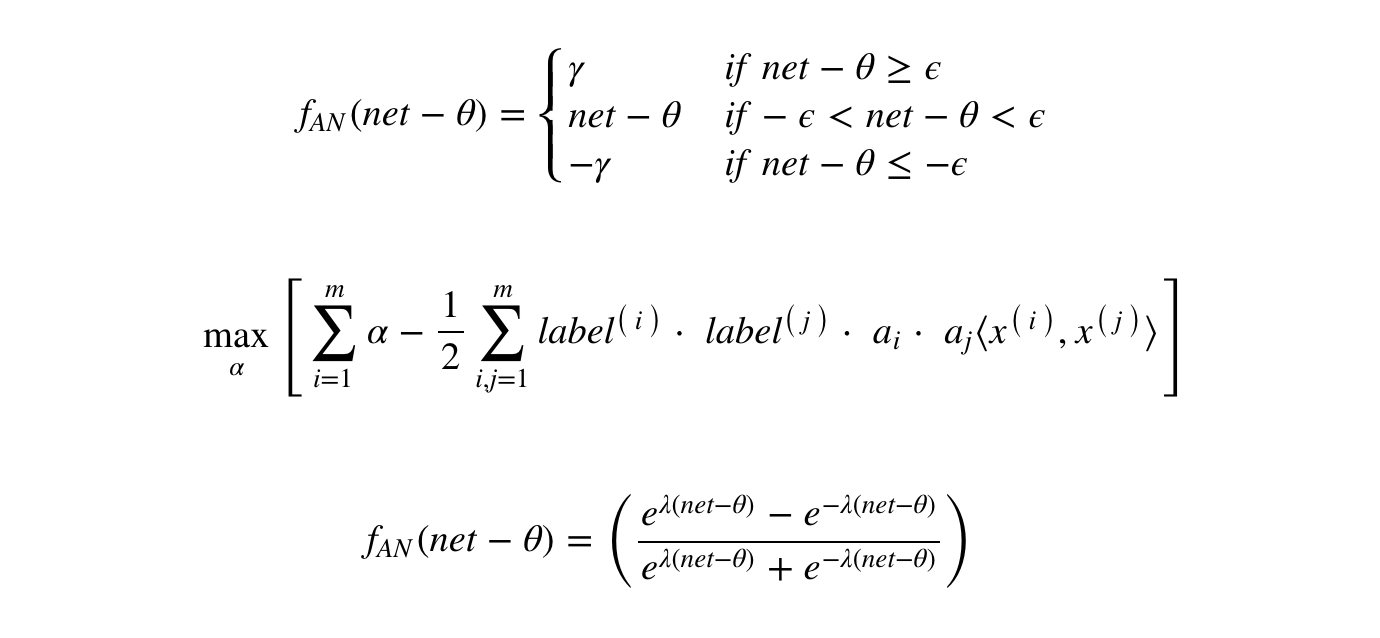
Lý thuyết xác suất :Đây là một ví dụ để kiểm tra kiến thức hiện tại của bạn về lý thuyết xác suất: Phân loại với xác suất có điều kiện.
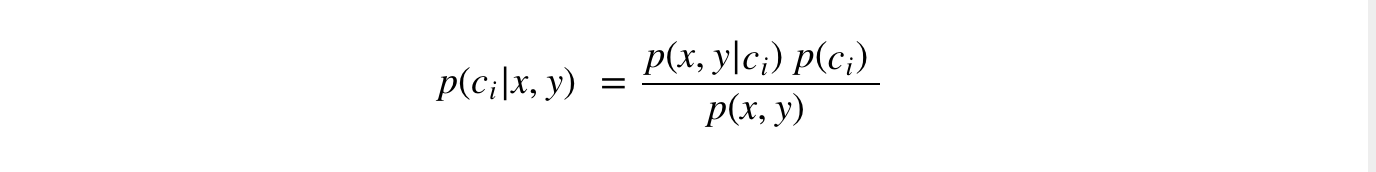
Với những định nghĩa này, chúng ta có thể xác định quy tắc phân loại Bayes :
- Nếu P(c1|x, y) > P(c2|x, y) , c1 .
- Nếu P(c1|x, y) < P(c2|x, y) , c2 .
Tối ưu hoá :
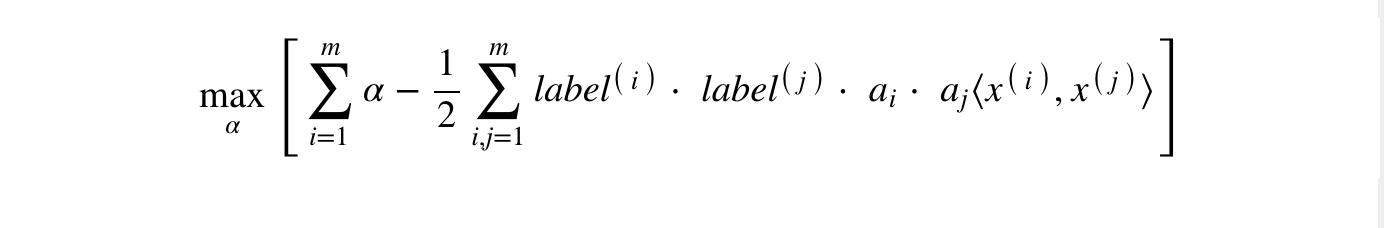
Tuân theo các ràng buộc sau:
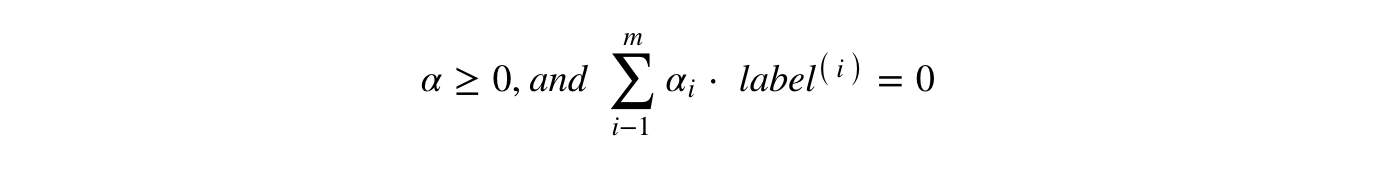
Nếu bạn có thể đọc và hiểu những điều trên, bạn đã sẵn sàng.
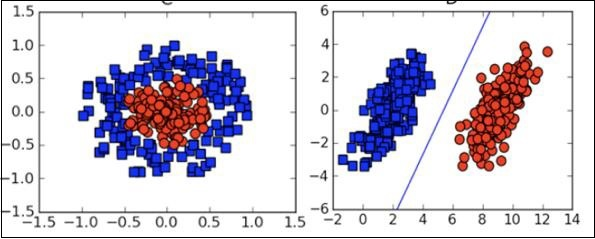
Visualization
Trong nhiều trường hợp, bạn sẽ cần hiểu các loại biểu đồ trực quan khác nhau để hiểu phân phối dữ liệu của bạn và diễn giải kết quả đầu ra của thuật toán.
Bên cạnh những khía cạnh lý thuyết trên về học máy, bạn cần có kỹ năng lập trình tốt để viết mã các thuật toán đó.Vậy để thực hiện ML cần những gì? Chúng ta hãy xem xét vấn đề này trong bài tiếp theo.
Bài 13: Machine Learning - Implementing - AI - Machine Learning cơ bản
Để phát triển các ứng dụng ML, bạn sẽ phải quyết định về nền tảng, IDE và ngôn ngữ để phát triển. Có một số lựa chọn có sẵn. Hầu hết trong số này sẽ đáp ứng yêu cầu của bạn một cách dễ dàng vì tất cả chúng đều cung cấp việc triển khai các thuật toán AI đã được thảo luận cho đến nay.Nếu bạn đang tự phát triển thuật toán ML, bạn cần hiểu kỹ các khía cạnh sau:Ngôn ngữ bạn chọn - điều này về cơ bản là bạn thành thạo một trong những ngôn ngữ được hỗ trợ trong phát triển ML.IDE mà bạn sử dụng - Điều này sẽ phụ thuộc vào mức độ quen thuộc của bạn với các IDE hiện có và mức độ thoải mái của bạn.Nền tảng phát triển - Có một số nền tảng có sẵn để phát triển và triển khai. Hầu hết trong số này là miễn phí để sử dụng. Trong một số trường hợp, bạn có thể phải trả phí bản quyền vượt quá số lượng sử dụng nhất định. Dưới đây là danh sách ngắn gọn về lựa chọn ngôn ngữ, IDE và nền tảng để bạn sẵn sàng tham khảo.
1. Lựa chọn ngôn ngữ :
Danh sách các ngôn ngữ hỗ trợ phát triển ML :
- Python
- R
- Matlab
- Octave
- Julia
- C++
- C
Danh sách này về cơ bản không toàn diện; tuy nhiên, nó bao gồm nhiều ngôn ngữ phổ biến được sử dụng trong phát triển ML. Tùy thuộc vào mức độ sử dụng thông thạo ngôn ngữ của bạn, hãy chọn một ngôn ngữ để phát triển các mô hình của bạn và thử nghiệm.
2. IDEs :
- R Studio
- Pycharm
- iPython/Jupyter Notebook
- Julia
- Spyder
- Anaconda
- Rodeo
- Google –Colab
Danh sách trên không phải là toàn diện. Mỗi người đều có những ưu điểm và phẩm chất riêng. Người đọc được khuyến khích thử các IDE khác nhau này trước khi thu hẹp lại thành một IDE duy nhất.
3. Platforms:
- IBM
- Microsoft Azure
- Google Cloud
- Amazon
- Mlflow
Một lần nữa danh sách này không đầy đủ. Người đọc được khuyến khích đăng ký các dịch vụ nói trên và tự mình dùng thử
Bài 14: Khởi đầu với neural network - AI - Machine Learning cơ bản
Để máy tính có thể phân biệt các thứ, chúng cần phải được huấn luyện để học ra các khuôn mẫu, đặc trưng của dữ liệu hay còn gọi là các pattern. Ví dụ như việc phân biệt các hành động như đi bộ, chạy hay đi xe đạp có thể cho máy phân biệt bằng cách nhìn vào dữ liệu của các cảm biến tốc độ, gia tốc, hướng xoay,.. Tất nhiên những đặc trưng này phải được trích chọn một cách tự động.Để biết cách thức hoạt động của neural network, hãy nhìn vào chuỗi số sau.
X = -1, 0, 1, 2, 3, 4
Y = -3, -1, 1, 3, 5, 7Nếu để ý hai chuỗi này, ta thấy nễu X tăng 1, Y tăng lên 2 nên có thể Y = 2X, tuy nhên nếu Y = 2X thì giá trị bị lệch 1 giữa Y và 2X. Vậy phải tăng giá trị 2X lên 1. Công thức cuối cùng là Y = 2X + 1. Đây chính là đặc trưng của dữ liệu mà ta cần tìm. Và đây cũng chính là quá trình tìm ra đặc trưng của neural network, chỉ khác là nó chạy trong đầu các bạn thôi. Sau đây mình sẽ hướng dẫn các bạn cách triển khai các bước này trên Tensorflow để tìm ra mối quan hệ giữa X và Y.Lưu ý: Về việc cài đặt tensorflow, các bạn có thể thực hiện theo hướng dẫn trên trang chủ củatensorflow. Hoặc bạn có thể sử dụng Colabđã được cài đặt đầy đủ môi trường bao gồm cả tensorflow.
Import một số thư viện cần thiết.
Tensorflow là thư viện giúp ta triển khai mô hình, còn Numpy giúp đơn giản việc biểu diễn dữ liệu.
import tensorflow as tf
import numpy as np
from tensorflow import kerasĐịnh nghĩa một neural network
Định nghĩa một mạng neural đơn giản chỉ có 1 layer, trong layer chỉ có 1 neuron nhận 1 input.
- tf.keras.Sequential giúp ta định nghĩa một chuỗi của các layer
- keras.layers.Dense định nghĩa một layer.
model = tf.keras.Sequential([keras.layers.Dense(units=1, input_shape=[1])])Model trên mới chỉ là khai báo một mạng neural. Để có thể huấn luyện mạng này, ta cần kết hợp nó với hai hàm khác là loss và optimizer.
- Hàm loss sẽ giúp xác định xem đầu ra của mô hình đã tốt so với kết quả chưa.
- Hàm optimizer sẽ sử dụng kết quả hàm loss để tối ưu mô hình để cho ra kết quả tốt hơn.
model.compile(optimizer='sgd', loss='mean_squared_error')Tạo dữ liệu huấn luyện cho mô hình
Thư viện Numpy cung cấp nhiều cách biểu diễn dữ liệu tiêu chuẩn. Để tạo ra dữ liệu để input vào mô hình đã khai báo bên trên, ta sử dụng hàm np.array[]
X = np.array([-1.0, 0.0, 1.0, 2.0, 3.0, 4.0], dtype=float)
Y = np.array([-3.0, -1.0, 1.0, 3.0, 5.0, 7.0], dtype=float)Huấn luyện neural network
Quá trình huấn luyện được thực hiện bởi hàm model.fit. Hàm này sẽ thực hiện duyệt qua tập dữ liệu, thực hiện tính toán ouput từ input, đo đạc lỗi sử dụng hàm loss, tối ưu lại mô hình sử dụng hàm optimizer và sau đó lặp lại quá trình đó. Việc duyệt qua hết một lần dữ liệu được gọi là thực hiện xong một epoch.
model.fit(X, Y, epochs=500)Sau khi mô hình được huấn luyện xong, nó đã học được đặc trưng của dữ liệu, mối quan hệ giữa X và Y. Giờ ta có thể sử dụng hàm model.predict để tìm ra giá trị Y khi truyền vào một giá trị X.
model.predict([10.0])
# Output: 18.980341Nhìn vào đây bạn có thể thắc mắc là tại sao giá trị đầu ra không phải là 19 mà chỉ gần với 19. Bạn có thể hiểu đơn giản thế này. Mạng neural học bằng cách đo lương sai khác giữa đầu ra của mô hình và kết quả thực tế. Sự đo lường này có sai số dẫn tới kết quả cuối cùng cũng có sai số. Tất nhiên sai số sẽ được giảm đi rất nhiều nếu bộ dữ liệu đủ lớn. Ở đây bộ dữ liệu chỉ có 6 điểm nên sai số như thế này là chấp nhận được.Chúc mừng! Bạn vừa triển khai xong một mô hình học máy chỉ với vài dòng code. Nhìn vào đây bạn có thể thấy rõ sự khác biệt giữ mô hình lập trình truyền thống và lập trình học máy như đã giới thiệu ởbài 1. Có một số khái niệm có thể lạ lẫm với bạn trong bài này như layer, loss, optimizer,... Nhưng đừng lo, qua loạt bài này, các bạn sẽ hiểu chi tiết chúng là gì và cách sử dụng chúng trong các trường hợp ra sao. Toàn bộ code của bài học này bạn có thể truy cập ở đây. Happy learning!
Bài 15: Xử lý ảnh sử dụng Neural Network - AI - Machine Learning cơ bản
Trong bài trước chúng ta vừa triển khai một mô hình mạng neural network đơn giản học từ các điểm dữ liệu (x, y) để tìm mô hình mối quan hệ giữa x và y, mô hình này sau đó được sử dụng để tìm y khi cho x. Chắc tới đây các bạn cũng đã nhận thấy sự khác biệt giữa mô hình lập trình theo giải thuật và mô hình lập trình học máy. Mô hình xây dựng ở bài trước khá đơn giản nhưng đây là nền tảng để xử lý những bài toán phức tạp hơn như x có thể là một bức ảnh, y là nhãn của bức ảnh đó ví dụ như giày, quần hay áo,... Các thao tác nhận dạng ảnh với con người thực sự rất đơn giản nhưng với máy tính thì thực sự rất phức tạp. Máy tính sẽ phải nhìn vào tất cả các điểm ảnh, và từ các điểm ảnh đó đưa ra kết quả đầu ra, việc định nghĩa sẵn luật để nhận dạng hiệu quả gần như là bất khả thi. Trong bài này, chúng ta sẽ cùng nhau giải quyết bài toán nhận dạng ảnh đồ vật sử dụng neural network.Nhận dạng ảnh là một trong những bài toán con trong lĩnh vực Computer Vision, đây là lĩnh vực giúp máy tính hiểu nội dung của ảnh. Nhìn vào hình 1, bạn có thể dễ dàng phân biệt các đồ vật cũng như tên gọi của chúng, tuy nhiên làm thế nào để dạy một em bé 2 tuổi nói đâu là đồ vật gì? Một cách thực tế nhất đó là đưa em bé thật nhiều ảnh của các đồ vật này và nói tên của những đồ vật đó. Đây cũng chính là các mà ta sẽ dạy máy.

Tập dữ liệu có tên Fashion MNISTcung cấp cho chúng ta 70k ảnh của 10 đồ vật khác nhau . Mỗi ảnh có kích thước 28*28 pixels. Mỗi điểm ảnh có giá trị màu từ 0 tới 255. Tổng cộng cần 784 bytes để biểu diễn mỗi ảnh. Tensorflow cung cấp sẵn hàm để đơn giản hoá việc load tập dữ liệu này. Hàm load_data() trả về tập các list gồm ảnh và nhãn của các ảnh đó. Để ý ở đây hàm load_data trả về hai loại dữ liệu là train và test. Trong machine learning, một chiến lược để huấn luyện mô hình đó là chia tập dữ liệu làm hai phần là train và test. Tập trainn được sử dụng để huấn luyện mô hình, test là để kiểm tra mô hình với những dữ liệu mà mô hình chưa từng được nhìn thấy. Kết quả của mô hình đánh giá trên tập test sẽ mang tính khách quan và chính xác hơn.
from tensorflow import keras
fashion_mnist = keras.datasets.fashion_mnist
(training_images, training_labels), (test_images, test_labels) = fashion_mnist.load_data()Hiển thị một điểm dữ liệu trong tập dữ liệu này. Nhãn của điểm dữ liệu này có giá trị là 9.
plt.imshow(train_images[0])
print(training_images[0])
print("Label id:", training_labels[0])
Để quá trình huấn luyện mô hình được nhanh hơn, các thao tác chuẩn hoá lại dữ liệu thường được áp dụng. Một trong những thao tác chuẩn hoá phổ biến được áp dụng trong xử lý ảnh là đưa toàn bộ giá trị điểm ảnh về khoảng 0 -> 1.
training_images = training_images / 255.0
test_images = test_images / 255.0Mô hình sử dụng để nhận dạng ảnh bao gồm các thành phần sau:Sequenntial: Giúp định nghĩa các layer cho mạng neural. Dữ liệu sẽ lần lượt được đưa qua và biến đổi trong các layer nàyFlatten: Giúp biến dữ liệu dạng ma trận thành vector. Ví dụ các ảnh hai chiều (28*28) ở đây sau khi đi qua Flatten sẽ biến thành dữ vector 784 chiềuDense: Một tầng ẩn chứa các node hay còn gọi là các neuron, các neuron này kết nối tới toàn bộ các node ở tầng phía trước. Ví dụ ở đây là 128 neuron, mỗi neuron kết nối tới 784 giá trị điểm ảnh ở tầng phía trước là Flatten. Mỗi neuron có một hàm gọi là activation hay còn gọi là hàm kích hoạt. Hiểu đơn giản là nếu giá trị input vượt quá một giá trị ngưỡng nào đó, hàm này sẽ ouput tín hiệu kích hoạt và ngược lại.Relu là một hàm kích hoạt có công thức y = max(0, x). Hàm này chỉ cho phép tín hiệu được truyền qua nếu giá trị truyền vào lớn hơn 0.Softmax hàm kích hoạt nhận đầu vào là chuỗi các giá trị, hàm này sẽ biến đổi chuỗi để tăng sự khác biệt giữa các phần tử trong chuỗi đầu vào. Giá trị nào cao vẫn cao, thấp vẫn thấp, nhưng cộng tổng lại bằng 1. Hàm tác động này rất hay được sử dụng trong các bài toán phân loại.
model = tf.keras.models.Sequential(
[
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(optimizer=tf.optimizers.Adam(),
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)Huấn luyện mô hình
model.fit(training_images, training_labels, epochs=5)
Epoch 1/5
1875/1875 [==============================] - 3s 2ms/step - loss: 0.4938 - accuracy: 0.8246
Epoch 2/5
1875/1875 [==============================] - 3s 2ms/step - loss: 0.3737 - accuracy: 0.8661
Epoch 3/5
1875/1875 [==============================] - 3s 2ms/step - loss: 0.3353 - accuracy: 0.8779
Epoch 4/5
1875/1875 [==============================] - 3s 2ms/step - loss: 0.3126 - accuracy: 0.8856
Epoch 5/5
1875/1875 [==============================] - 3s 2ms/step - loss: 0.2953 - accuracy: 0.8909Mô hình huấn luyện đạt được độ chính xác trên tập train là 89%. Tuy đây không phải là kết quả thực sự tốt nhưng chỉ với một mô hình thực sự rất đơn giản và chỉ mất 5 lần duyệt qua dữ liệu thì đây là kết quả có thể chấp nhận đượcSau khi đã huấn luyện mô hình, ta có thể đánh giá chất lượng sử dụng tập test
model.evaluate(test_images, test_labels)
313/313 [==============================] - 0s 1ms/step - loss: 0.3541 - accuracy: 0.8697
[0.35407450795173645, 0.869700014591217]Mô hình đạt độ chính xác trên tập test là 86%, thấp hơn một chút so với tập train. Đây là điều hoàn toàn hợp lý. Độ chính xác trên tập train cao hơn vì mô hình đã nhìn thấy những điểm dữ liệu đó, còn trên tập test là những điểm dữ liệu mới mà mô hình chưa từng nhìn thấy.Sử dụng mô hình để dự đoán nhãn của một ảnh trong tập test
predict_result = model.predict(np.array([test_images[11]]))
print("Label image: ", test_labels[11])
print(predict_result)
#Label image: 5
#[[1.6722430e-05 4.4020371e-08 5.3876643e-06 4.0128889e-08 5.6786785e-06 9.9806458e-01 5.0837298e-05 1.0092560e-03 8.7840099e-06 8.3871983e-04]]Các bạn có thể thấy giá trị output trông khá lạ. Thực ra nhìn kỹ các bạn sẽ thấy đây là một mảng gồm 10 giá trị. Những giá trị này chính là phân phối xác suất của 10 nhãn. Giá trị xác suất nào cao nhất thì nhãn dự đoán chính ở vị trí đó. Trong ví dụ này thì vị trí có giá trị xác suất cao nhất là 5. Và giá trị này cũng trùng khớp với nhãn thực tế của ảnh. Mô hình đã dự đoán đúng.Trong bài này, các bạn đã học được cách sử dụng neural network để nhận dạng các vật thể. Mô hình này thực ra khá giống với mô hình triển khai ở bài trước, nhưng được nâng cấp hơn về số lượng neron ở tầng ẩn. Các bạn có thể thực hành tăng kích thước tầng ẩn hoặc thậm chí tăng số lượng tầng ẩn để thấy được sự tác động của kích thước mô hình tới chất lượng của dự đoán.
Bài 16: Mạng neuron tích chập - AI - Machine Learning cơ bản
Từ năm 1996, siêu máy tính Deep Blue của IBM đã đánh bại con người trong trò chơi cờ vua những tới tận những năm gần đây, máy tính mới có thể đạt tới ngưỡng của con người trong việc nhận dạng những thứ rất đơn giản như ảnh một chú cún hay lời nói bên trong âm thanh. Tại sao điều này rất dễ dàng với con người nhưng lại là thách thức với máy tính?Câu trả lời là nhận thức của chúng ta xảy ra bên ngoài ý thức, nó diễn ra một cách tự nhiên trong các mô-đun thị giác, thính giác và các giác quan khác trong não của chúng ta. Lúc mà ý thức của chúng ta quyết định đâu là cái gì, tín hiệu đã được chuyển hoá hết thành thông tin có ý nghĩa rồi. Lấy ví dụ khi bạn nhìn vào một chú cún, bạn không thể quyết định loại bỏ chú cún đó ra trong những hình ảnh bạn nhìn thấy.Mạng neuron tích chập (Convolutional Neural networks - CNN) xuất hiện trong những nghiên cứu về vỏ não thị giác từ năm 1980. Những năm gần đây, năng lực tính toán của máy tính được nâng cao, dữ liệu trong thời đại số bùng nổ cộng với những nghiên cứu mới trong việc huấn luyện mạng neuron hiệu quả đã đưa CNN đạt được hiệu suất như con người trong nhiều lĩnh vực cần xử lý hình ảnh trực quan như tìm kiếm ảnh, xe tự lái, hệ thống phân loại ảnh video,... Trong bài này mình sẽ cùng các bạn tìm hiểu những thành phần làm lên sự thành công của mạng neuron tích chập này.Nghiên cứu về vỏ não thị giác cho thấy, một số neuron thần kinh chỉ phản ứng với một vùng nhỏ của bức ảnh, trong khi một số neuron khác lại phản ứng với vùng ảnh to hơn, những vùng to này là kết hợp của các vùng ảnh nhỏ phía trước. Ngoài ra một số neuron phản ứng với những đường kẻ nằm ngang, số khác lại phản ứng với những đường nằm dọc (Hình 1).
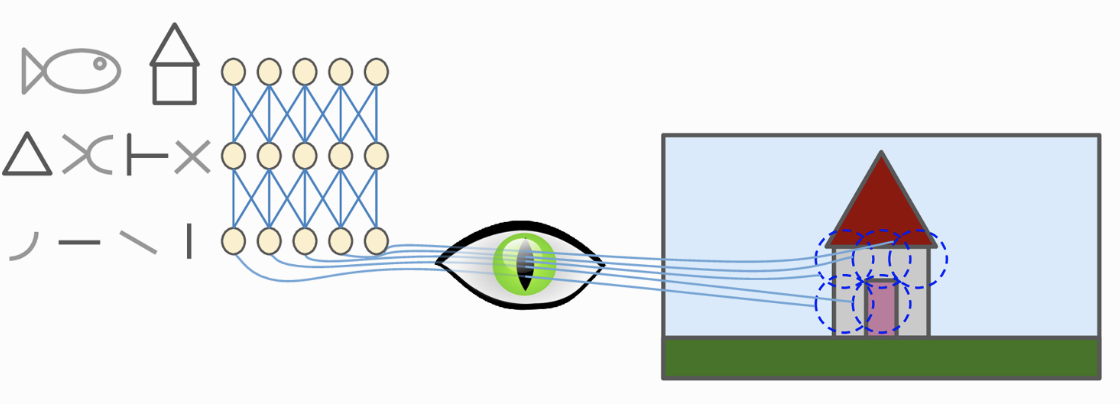
Những quan sát này dẫn tới một ý tưởng là những neuron tầng cao tổng hợp những đặc trưng từ tầng thấp, nhưng mỗi neuron chỉ nhìn vào một phần của tầng tầng bên dưới nó chứ không tổng hợp toàn bộ thông tin từ tầng dưới. Nghiên cứu về vỏ não thị giác đã truyền cảm hứng để năm 1998, Yann Lecun đã giới thiệu kiến trúc CNN LeNet với thành phần cốt lõi là hai khối Convolutional và Pooling. Hãy cùng tìm hiểu hai khối này bao gồm những gì.
Convolutional layer
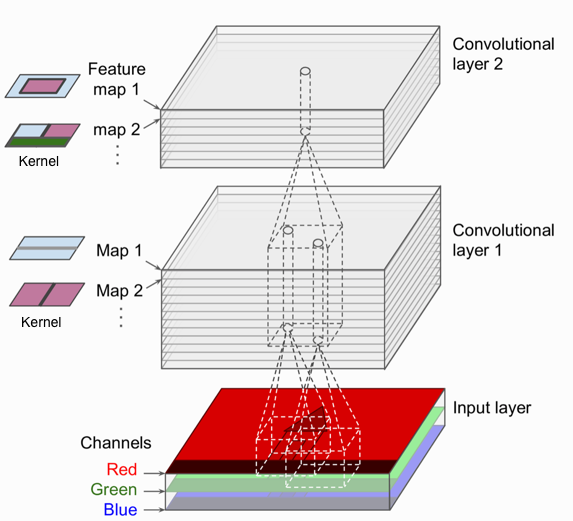
Tầng Convolutional là khối quan trọng nhất trong một mạng CNN. Các neuron ở tầng đầu tiên không kết nối trực tiếp tới toàn bộ các pixel của ảnh đầu vào mà chỉ những pixel trong một vùng nhỏ. Tương tự như thế, các neuron ở tầng cao không kết nối trực tiếp tới toàn bộ tầng thấp mà chỉ kết nối tới một phần các neuron tầng dưới nó. Kiến trúc này sẽ cho phép các tầng thấp tập trung để trích xuất thông tin cấp thấp, còn tầng cao tổng hợp những thông tin trừu tượng hơn (Hình 2). Cách xử lý như này cũng giống với con người, điều đó giải thích lý do tại sao mạng CNN rất phù hợp cho xử lý ảnh.
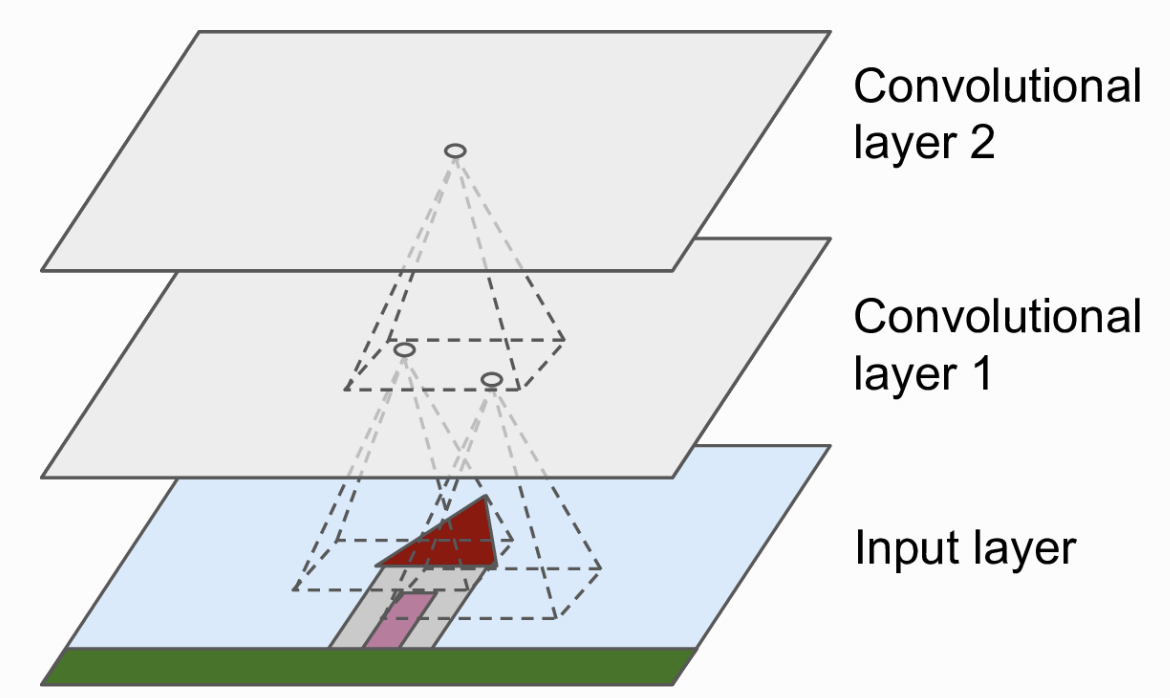
Kernel
Chi tiết hơn. Mỗi neuron tại vị trí hàng i cột j sẽ kết nối với các neuron tầng dưới thuộc hàng từ i tới i + fh - 1, cột từ j tới j + fw -1. với fh và fw là chiều cao và chiều rộng của kernel (góc nhìn của một neuron). Để layer tầng cao có số neuron giống với tầng dưới nhằm tiện cho việc tính toán, trong thực tế ta sẽ thêm một số hàng và cột có giá trị 0 xung quanh tầng dưới (Zero padding). (Hình 3)
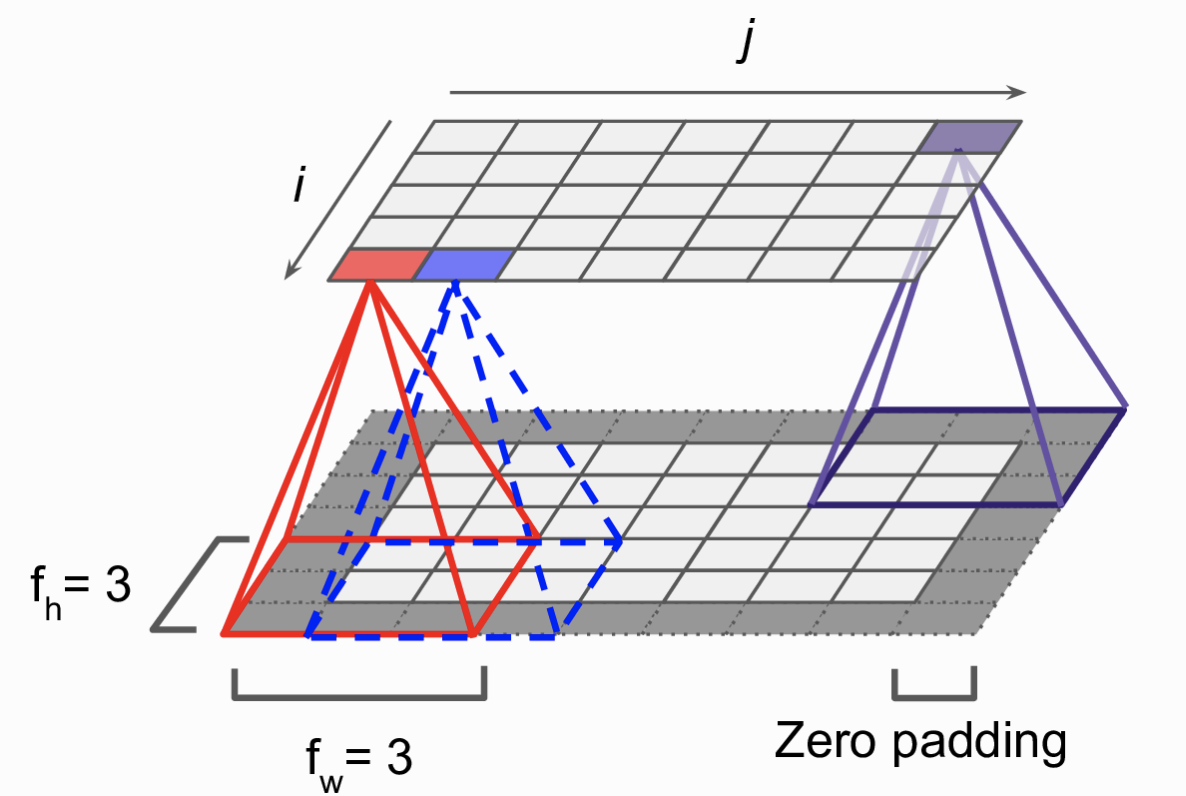
Stride (Bước nhảy)
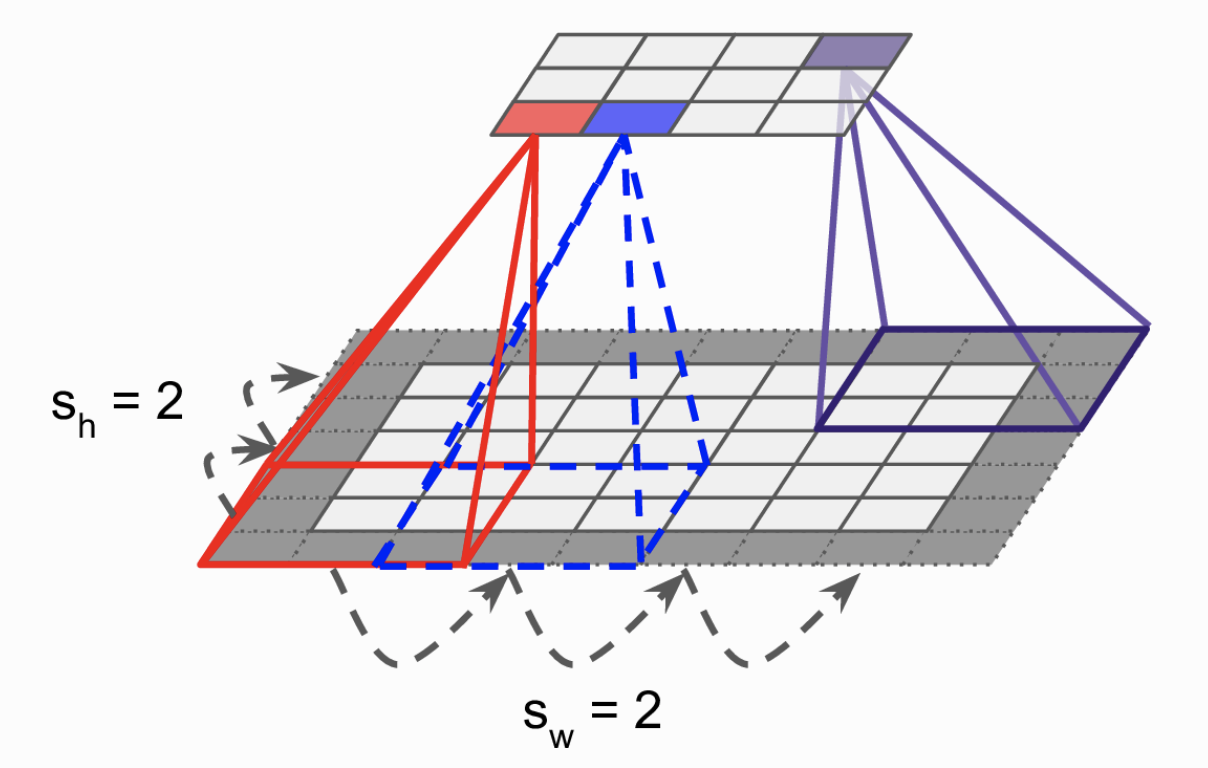
Có thể thực hiện việc trích chọn đặc trưng tầng thấp thành thành đặc trưng tầng cao có kích thước nhỏ hơn bằng việc nhảy cóc việc quét các kernel qua ảnh. Hình 3 bước nhảy của các kernel là 1. Hình 4 biểu thị bước nhảy 2. Các bạn có thể thấy số lượng neuron ở tầng trên thấp hơn đáng kể ở tầng dưới. Khi đó mỗi neuron tại vị trí hàng i cột j sẽ kết nối với các neuron tầng dưới thuộc hàng từ i * sh tới i * sh + fh - 1, cột từ j * sw tới j * sw + fw -1. với fh và fw. Với sh là bước nhảy theo chiều dọc và sw là bước nhảy theo chiều ngang
Feature map
Kernel được tính toán trên ảnh đầu vào, duyệt qua toàn bộ ảnh và cho ra một ma trận mới (bằng hoặc nhỏ hơn ma trận ảnh đầu vào tuỳ thuộc vào bước nhảy và kích thước kernel). Ma trận đầu ra này còn được gọi là Feature map. Với một ảnh đầu vào ta có thể sử dụng nhiều kernel, mỗi kernel sẽ cho ra một Feature map khác nhau. Hình 5.
Bạn có thể tưởng tượng ảnh đầu vào là một tập 3 Feature map, mỗi feature map đại diện cho một kênh màu. Sau đó sử dụng n kernel để cho ra một tập n Feature map cho tầng đầu tiên, và cứ thế sẽ có feature map cho các tầng tiếp theo. Khái niệm kernel bây giờ không chỉ có 2 chiều cao và rộng nữa mà sẽ thêm chiều sâu, đó chính là số lượng feature map ở tầng dưới. Lấy ví dụ kernel ở tầng đầu tiên sẽ có kích thước là [sh, fw, 3] với 3 chính là số kênh màu của ảnh đầu vào.
Triên khai tính toán Convolutional trên tensorflow
Import một số thư viện cần thiết
from sklearn.datasets import load_sample_image
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as pltLoad ảnh và tính toán các tham số của ảnh
flower = load_sample_image("flower.jpg")
batch_size = 1
height, width, channels = flower.shapeTạo kernel
kernels = np.zeros(shape=(7, 7, channels, 2), dtype=np.float32)
kernels[:, 3, :, 0] = 1 # vertical line
kernels[3, :, :, 1] = 1 # horizontal lineTính toán phép nhân chập sử dụng tensorflow
outputs = tf.nn.conv2d([flower], kernels, strides=1, padding="SAME")Hiển thị kết quả đầu ra sử dụng matplotlib
fig=plt.figure(figsize=(16, 48))
fig.add_subplot(1, 3, 1)
plt.imshow(flower, cmap="gray") # ảnh gốc
fig.add_subplot(1, 3, 2)
plt.imshow(outputs[0, :, :, 0], cmap="gray") # feature map ngang
fig.add_subplot(1, 3, 3)
plt.imshow(outputs[0, :, :, 1], cmap="gray") # feature map dọc
plt.show()
Ở đây các kernel chúng ta tự định nghĩa. Tuy nhiên trong thực tế, những kernel này sẽ được tự động học dựa trên dữ liệu huấn luyện. Phần tiếp theo chúng ta sẽ tìm hiểu thành phần quan trọng thứ hai trong một mạng neuron tích chập đó là thành phần Pooling
Bài 17: Machine Learning - Kết luận - AI - Machine Learning cơ bản
Hướng dẫn này đã giới thiệu cho bạn cơ bản về machine learning. Bây giờ, bạn biết rằng Học máy là một kỹ thuật đào tạo máy móc để thực hiện các hoạt động mà bộ não con người có thể làm, mặc dù nhanh hơn và tốt hơn một chút so với con người bình thường. Ngày nay chúng ta đã thấy rằng những cỗ máy có thể đánh bại những nhà vô địch của con người trong các trò chơi như Cờ vua, AlphaGO, những trò chơi được coi là rất phức tạp. Bạn thấy rằng máy móc có thể được đào tạo để thực hiện các hoạt động của con người trong một số lĩnh vực và có thể hỗ trợ con người sống tốt hơn.
Học máy có thể là Học có giám sát hoặc học không giám sát. Nếu bạn có lượng dữ liệu ít hơn và dữ liệu được gắn nhãn rõ ràng để đào tạo, hãy chọn Học có giám sát. Học không giám sát thường mang lại hiệu suất và kết quả tốt hơn cho các tập dữ liệu lớn. Nếu bạn có một bộ dữ liệu khổng lồ dễ dàng có sẵn, hãy sử dụng các kỹ thuật học sâu. Bạn đã biết đến các khải niệm về Học tăng cường và Học củng cố sâu. Ngoài ra bạn đã biết Mạng thần kinh là gì, các ứng dụng và hạn chế của chúng.
Cuối cùng, khi nói đến việc phát triển các mô hình học máy của riêng bạn, hãy xem xét các lựa chọn về ngôn ngữ phát triển, IDE và nền tảng. Điều tiếp theo mà bạn cần làm là bắt đầu học và thực hành từng kỹ thuật học máy. Kiến thức học máy bao la nghĩa là có bề rộng, nhưng nếu xét theo chiều sâu, mỗi chuyên đề có thể học trong vài giờ. Mỗi chủ đề độc lập với nhau. Bạn cần xem xét từng chủ đề một, tìm hiểu, thực hành và triển khai / các thuật toán trong đó bằng cách sử dụng ngôn ngữ lựa chọn của bạn. Đây là cách tốt nhất để bắt đầu học Máy học. Thực hành từng chủ đề một, bạn sẽ sớm có được chiều rộng mà cuối cùng cần phải có của một chuyên gia về Máy học.
Chúc bạn học tốt!
Theo dõi VnCoder trên Facebook, để cập nhật những bài viết, tin tức và khoá học mới nhất!
- Bài 1: Giới thiệu về Machine Learning
- Bài 2: Machine Learning - AI ngày nay có thể làm gì?
- Bài 3: Machine Learning - AI truyền thống
- Bài 4: Machine Learning - Machine Learning là gì?
- Bài 5: Machine Learning - Phân loại
- Bài 6: Machine Learning - Phân loại (p2)
- Bài 7: Machine Learning - Supervised Learning
- Bài 8: Machine Learning - Thư viện Scikit learn
- Bài 9: Machine Learning - Unsupervised learning
- Bài 10: Machine Learning - Artificial Neural Networks
- Bài 11: Machine Learning - Deep Learning
- Bài 12: Machine Learning - Skills
- Bài 13: Machine Learning - Implementing
- Bài 14: Khởi đầu với neural network
- Bài 15: Xử lý ảnh sử dụng Neural Network
- Bài 16: Mạng neuron tích chập
- Bài 17: Machine Learning - Kết luận
- Bài 18: Rút gọn : Phần 1
- Bài 19: Rút gọn - phần 2
- Bài 20: Rút gọn - phần 3