TÌm hiểu về Supervised Learning, Supervised Learning là gì ?
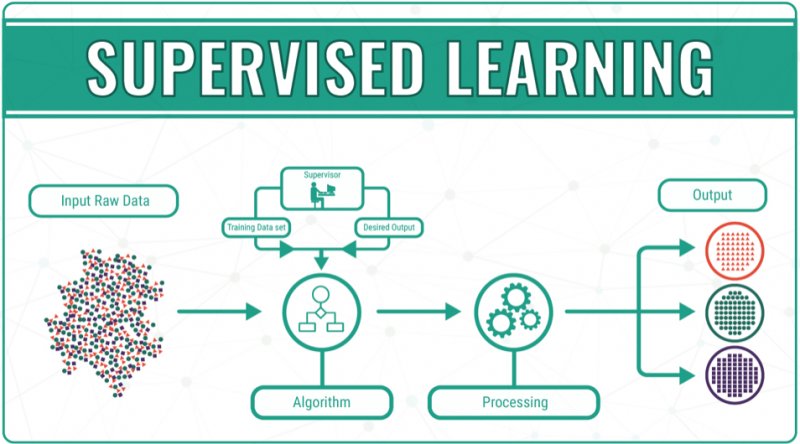
Supervised Learning trong Machine Learning là gì? Trong Supervised Machine Learning, bạn huấn luyện, đào tạo cho máy của bạn sử dụng dữ liệu được “dán nhãn”. Điều đó có nghĩa là một số dữ liệu đã được gắn thẻ với câu trả lời chính xác. Điều đó giống như bạn đang tự học nhưng lại có mặt của người giám sát hoặc giáo viên.
Một thuật toán Supervised Learning, học từ các dữ liệu đã được dán nhãn, giúp bạn dự đoán kết quả cho dữ liệu không lường trước được.
Xây dựng thành công, nhân rộng và triển khai các mô hình học máy được giám sát chính xác cần có thời gian và chuyên môn kỹ thuật từ một nhóm các nhà khoa học dữ liệu có tay nghề cao. Hơn nữa, nhà khoa học dữ liệu phải xây dựng lại các mô hình để đảm bảo những hiểu biết được đưa ra vẫn đúng cho đến khi dữ liệu của nó thay đổi.
Trong hướng dẫn này, bạn sẽ học:
- Supervised Learning là gì?
- Supervised Learning hoạt động như thế nào.
- Các loại thuật toán của Supervised Learning.
- Supervised & Unsupervised cùng các công nghệ, kỹ thuật.
- Những thách thức trong Supervised Learning.
- Ưu điểm của Supervised Learning:
- Nhược điểm của việc học có giám sát
- Thực hành tốt nhất cho việc học có giám sát
Supervised Learning hoạt động như thế nào?
Ví dụ, bạn muốn đào tạo một cỗ máy để giúp bạn dự đoán bạn sẽ mất bao lâu để lái xe về nhà từ nơi làm việc. Tại đây, bạn bắt đầu bằng cách tạo một tập hợp dữ liệu được dán nhãn. Dữ liệu này bao gồm
- Điều kiện thời tiết
- Thời gian trong ngày
- Ngày lễ
- Chọn đường đi
Tất cả những chi tiết này là đầu vào của bạn. Đầu ra là lượng thời gian cần thiết để lái xe trở về nhà vào ngày cụ thể đó.

Theo bản năng, bạn biết rằng nếu trời mưa, thì bạn sẽ mất nhiều thời gian hơn để lái xe về nhà. Nhưng máy thì sẽ cần dữ liệu và số liệu thống kê.
Bây giờ chúng ta hãy xem làm thế nào bạn có thể phát triển một mô hình học tập có giám sát của ví dụ này để giúp người dùng xác định thời gian đi làm. Điều đầu tiên bạn cần tạo là một bộ huấn luyện. Tập huấn luyện này sẽ chứa tổng thời gian đi lại và các yếu tố tương ứng như thời tiết, thời gian, v.v. Dựa trên tập huấn luyện này, máy của bạn có thể thấy có mối quan hệ trực tiếp giữa lượng mưa và thời gian bạn sẽ về nhà.
Vì vậy, nó càng khẳng định rằng trời càng mưa, bạn sẽ lái xe càng lâu để trở về nhà. Nó cũng có thể thấy kết nối giữa thời gian bạn nghỉ làm và thời gian bạn sẽ đi trên đường.
Bạn càng gần 6 giờ tối. bạn càng mất nhiều thời gian để về nhà. Máy của bạn có thể tìm thấy một số mối quan hệ với dữ liệu được dán nhãn của bạn.
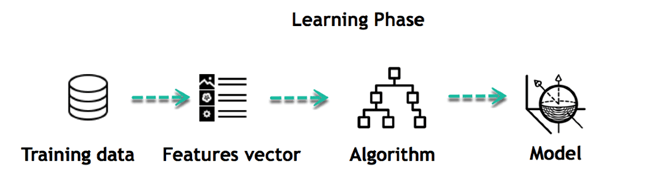
Đây là sự khởi đầu của Mô hình dữ liệu của bạn. Nó bắt đầu tác động như cách mưa ảnh hưởng đến cách mọi người lái xe. Nó cũng bắt đầu cho thấy rằng nhiều người đi du lịch trong một thời gian cụ thể trong ngày.
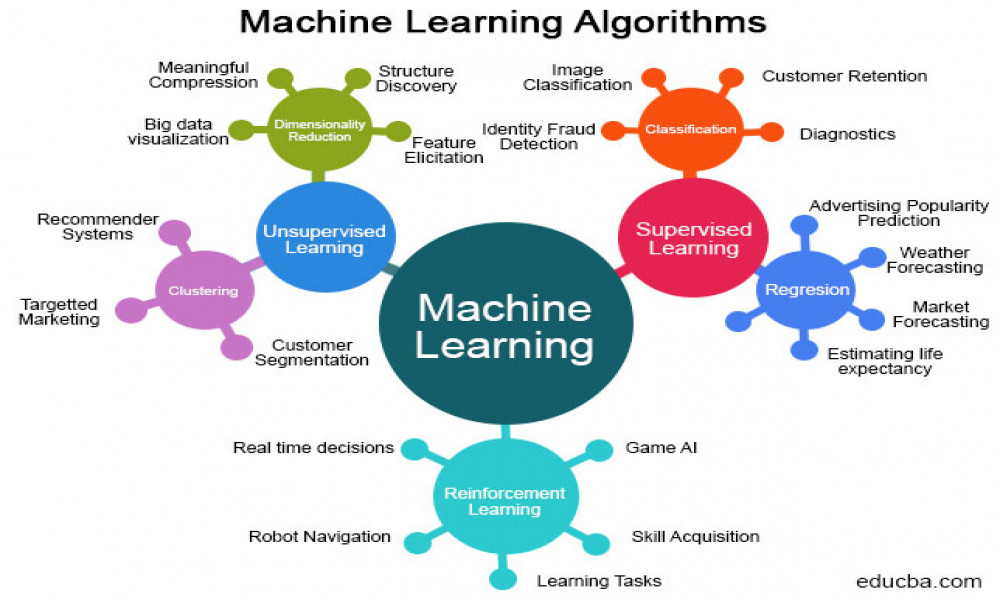
Các loại thuật toán học máy được giám sát
Hồi quy:
Kỹ thuật hồi quy dự đoán một giá trị đầu ra duy nhất sử dụng dữ liệu huấn luyện.
Ví dụ: Bạn có thể sử dụng hồi quy để dự đoán giá nhà từ dữ liệu đào tạo. Các biến đầu vào sẽ là địa phương, kích thước của một ngôi nhà, vv
Điểm mạnh: Đầu ra luôn có một diễn giải xác suất và thuật toán có thể được thường xuyên hóa để tránh bị thừa.
Điểm yếu: Hồi quy logistic có thể hoạt động kém khi có nhiều ranh giới quyết định phi tuyến tính. Phương pháp này không linh hoạt, vì vậy nó không nắm bắt được các mối quan hệ phức tạp hơn.
Hồi quy logistic:
Phương pháp hồi quy logistic được sử dụng để ước tính các giá trị rời rạc dựa trên một tập hợp các biến độc lập. Nó giúp bạn dự đoán xác suất xảy ra sự kiện bằng cách khớp dữ liệu với chức năng logit. Do đó, nó còn được gọi là hồi quy logistic. Vì nó dự đoán xác suất, giá trị đầu ra của nó nằm trong khoảng từ 0 đến 1.
Dưới đây là một vài loại thuật toán hồi quy
Phân loại:
Phân loại có nghĩa là nhóm đầu ra bên trong một lớp. Nếu thuật toán cố gắn nhãn đầu vào thành hai lớp riêng biệt, nó được gọi là phân loại nhị phân. Chọn giữa nhiều hơn hai lớp được gọi là phân loại đa lớp.
Ví dụ: Xác định xem có ai đó sẽ là người trả nợ cho khoản vay hay không.
Điểm mạnh: Cây phân loại thực hiện rất tốt trong thực tế
Điểm yếu: Không bị giới hạn, các cây riêng lẻ dễ bị quá mức.
Dưới đây là một vài loại Thuật toán phân loại
Phân loại Naïve Bayes
Mô hình Naïve Bayesian (NBN) rất dễ xây dựng và rất hữu ích cho các bộ dữ liệu lớn. Phương pháp này bao gồm các biểu đồ chu kỳ trực tiếp với một phụ huynh và một vài đứa trẻ. Nó giả định sự độc lập giữa các nút con tách khỏi cha mẹ của chúng.
Cây quyết định
Cây quyết định phân loại thể hiện bằng cách sắp xếp chúng dựa trên giá trị tính năng. Trong phương thức này, mỗi chế độ là tính năng của một thể hiện. Nó nên được phân loại và mỗi nhánh đại diện cho một giá trị mà nút có thể giả định. Nó là một kỹ thuật được sử dụng rộng rãi để phân loại. Trong phương pháp này, phân loại là một cây được gọi là cây quyết định.
Nó giúp bạn ước tính giá trị thực (chi phí mua xe, số lượng cuộc gọi, tổng doanh số hàng tháng, v.v.).
Hỗ trợ máy Vector
Máy vectơ hỗ trợ (SVM) là một loại thuật toán học tập được phát triển vào năm 1990. Phương pháp này dựa trên kết quả từ lý thuyết học thống kê được giới thiệu bởi v.v.
Máy SVM cũng chặt chẽkết nối với các hàm kernel là một khái niệm trung tâm cho hầu hết các nhiệm vụ học tập. Khung nhân và SVM được sử dụng trong nhiều lĩnh vực. Nó bao gồm truy xuất thông tin đa phương tiện, tin sinh học và nhận dạng mẫu.
Các kỹ thuật học máy được giám sát so với không giám sát
Dựa trên kỹ thuật học máy được giám sát Kỹ thuật học máy không giám sát
Thuật toán dữ liệu đầu vào được đào tạo sử dụng dữ liệu được dán nhãn. Các thuật toán được sử dụng đối với dữ liệu không được gắn nhãn
Độ phức tạp tính toán trong Supervised Learning là một phương pháp đơn giản hơn. Unsupervised Learning là phức tạp tính toán
Độ chính xác Phương pháp rất chính xác và đáng tin cậy. Phương pháp ít chính xác và đáng tin cậy.
Những thách thức trong Supervised Learning
Đây là những thách thức phải đối mặt trong Supervised Learning:
Tính năng nhập liệu không liên quan hiện tại dữ liệu đào tạo có thể cho kết quả không chính xác
Chuẩn bị dữ liệu và xử lý trước luôn là một thách thức.
Độ chính xác bị ảnh hưởng khi các giá trị không thể, không thể và không đầy đủ đã được nhập vào dưới dạng dữ liệu đào tạo
Nếu chuyên gia liên quan không có sẵn, thì cách tiếp cận khác là “vũ phu”. Điều đó có nghĩa là bạn cần nghĩ rằng các tính năng phù hợp (biến đầu vào) để huấn luyện máy. Nó có thể không chính xác.

Ưu điểm của Supervised Learning:
Học có giám sát cho phép bạn thu thập dữ liệu hoặc tạo đầu ra dữ liệu từ trải nghiệm trước đó
Giúp bạn tối ưu hóa tiêu chí hiệu suất bằng kinh nghiệm
Học máy được giám sát giúp bạn giải quyết các loại vấn đề tính toán trong thế giới thực.
Nhược điểm của Supervised Learning:
Ranh giới quyết định có thể được tập trung quá mức nếu tập huấn luyện của bạn không có ví dụ mà bạn muốn có trong một lớp
Bạn cần chọn nhiều ví dụ hay từ mỗi lớp trong khi bạn đang đào tạo trình phân loại.
Phân loại dữ liệu lớn có thể là một thách thức thực sự.
Đào tạo cho việc học có giám sát cần rất nhiều thời gian tính toán.
Thực hành tốt nhất cho Supervised Learning
Trước khi làm bất cứ điều gì khác, bạn cần phải quyết định loại dữ liệu nào sẽ được sử dụng làm tập huấn luyện
Bạn cần quyết định cấu trúc của hàm đã học và thuật toán học.
Gathere đầu ra tương ứng hoặc từ các chuyên gia của con người hoặc từ các phép đo
Tóm lược:
- Trong Supervised Learning, bạn huấn luyện máy sử dụng dữ liệu được “dán nhãn”.
- Bạn muốn đào tạo một cỗ máy giúp bạn dự đoán bạn sẽ mất bao lâu để lái xe về nhà từ nơi làm việc là một ví dụ về việc học có giám sát
- Hồi quy và Phân loại là hai loại kỹ thuật Supervised Learning.
- Supervised Learning là một phương pháp đơn giản hơn trong khi học tập không giám sát là một phương pháp phức tạp.
- Thách thức lớn nhất trong học tập có giám sát là tính năng nhập liệu không liên quan hiện tại có thể cho kết quả không chính xác.
- Ưu điểm chính của việc học có giám sát là nó cho phép bạn thu thập dữ liệu hoặc tạo ra dữ liệu đầu ra từ trải nghiệm trước đó.
- Hạn chế của mô hình này là ranh giới quyết định có thể bị giới hạn nếu tập huấn luyện của bạn không có ví dụ mà bạn muốn có trong một lớp.
- Là một cách thực hành tốt nhất trong việc giám sát việc học, trước tiên bạn cần quyết định loại dữ liệu nào sẽ được sử dụng làm tập huấn luyện.
Theo:
nordiccoder.com
Theo dõi VnCoder trên Facebook, để cập nhật những bài viết, tin tức và khoá học mới nhất!