Firebase ML Kit: Nhận dạng văn bản ( Text Recognition) trong Android
Với API nhận dạng văn bản của ML Kit, bạn có thể nhận dạng văn bản bằng bất kỳ ngôn ngữ gốc Latinh nào (và hơn thế nữa, với nhận dạng văn bản dựa trên đám mây).

1. Tổng quan
Nhận dạng văn bản là quá trình phát hiện và nhận dạng thông tin văn bản trong hình ảnh, video, tài liệu và các nguồn khác.
Có nhiều ứng dụng như Google Dịch , Google Keep , CamScanner , v.v ... sử dụng sức mạnh của nhận dạng văn bản để cung cấp một số tính năng tuyệt vời và hữu ích.
2. Nhận dạng văn bản của ML Kit
Nhận dạng văn bản của ML Kit cung cấp cả API trên thiết bị và trên nền tảng đám mây.
Bạn có thể chọn cái nào sẽ sử dụng tùy thuộc vào trường hợp sử dụng của bạn.

Trình nhận dạng văn bản của ML Kit phân đoạn văn bản thành các khối, dòng và thành phần.
- Khối là một tập hợp các dòng văn bản liền kề nhau, chẳng hạn như một đoạn hoặc cột.

- Line là một tập hợp các từ liền kề trên cùng một dòng.

- Phần tử là một tập hợp các ký tự chữ và số trên cùng một trục dọc.

3. Cài đặt
- Bước 1: Thêm Firebase vào ứng dụng của bạn
Bạn có thể thêm Firebase vào ứng dụng của mình bằng cách làm theo các bước được đề cập ở đây
- Bước 2: Bao gồm sự phụ thuộc
Bạn cần include ML Kit dependency trong build.gradle
dependencies {
// ...
implementation 'com.google.firebase:firebase-ml-vision:19.0.2'
}
- Bước 3: Chỉ định các mô hình ML (tùy chọn)
Đối với API trên thiết bị, bạn có thể định cấu hình ứng dụng của mình để tự động tải xuống các mô hình ML sau khi được cài đặt từ CH Play. Nếu không, mô hình sẽ được tải xuống trong lần đầu tiên bạn chạy trình phát hiện trên thiết bị.
Để bật tính năng này, bạn cần chỉ định các mô hình trong AndroidManifest.xml
<application ...>
...
<meta-data
android:name="com.google.firebase.ml.vision.DEPENDENCIES"
android:value="ocr" />
<!-- To use multiple models: android:value="ocr,model2,model3" -->
</application>
Bước 4: Nhận hình
ML Kit cung cấp một cách dễ dàng để nhận ra văn bản từ nhiều loại hình ảnh thích Bitmap, media.Image, ByteBuffer, byte[], hoặc một tập tin trên thiết bị. Bạn chỉ cần tạo một đối tượng FirebaseVisionImage từ các loại hình ảnh được đề cập ở trên và chuyển nó vào mô hình.
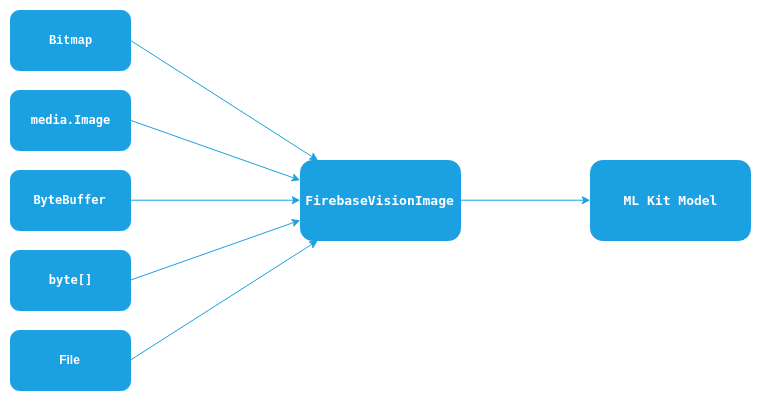
Ví dụ:
val image = FirebaseVisionImage.fromBitmap(bitmap)
Để tạo FirebaseVisionImage từ các loại hình ảnh khác, vui lòng tham khảo tài liệu
Bước 4:
Bây giờ, đã đến lúc chuẩn bị mô hình Nhận dạng văn bản
ML Kit cung cấp cả các mô hình trên thiết bị và trên nền tảng đám mây cho Nhận dạng văn bản.
Trên mẫu thiết bị
val textRecognizer = FirebaseVision.getInstance().onDeviceTextRecognizer
Mô hình dựa trên đám mây
val textRecognizer = FirebaseVision.getInstance().cloudTextRecognizer
Đối với mô hình Nhận dạng văn bản dựa trên đám mây, bạn cũng có thể cung cấp các ngôn ngữ khác nhau mà bạn muốn mô hình của mình phát hiện.
val options = FirebaseVisionCloudTextRecognizerOptions.Builder()
.setLanguageHints(Arrays.asList("en", "hi"))
.build()
val textRecognizer = FirebaseVision.getInstance().getCloudTextRecognizer(options)
Bước 5:
Cuối cùng, chúng ta có thể chuyển hình ảnh của mình cho mô hình để nhận dạng văn bản.
textRecognizer.processImage(image)
.addOnSuccessListener {
// Task completed successfully
}
.addOnFailureListener {
// Task failed with an exception
}
Bước 6: Trích xuất thông tin
Nếu nhận dạng văn bản thành công, bạn sẽ nhận được một đối tượng FirebaseVisionText trong addOnSuccessListener .FirebaseVisionText chứa tất cả các thông tin hiện tại văn bản trong hình ảnh.
Như đã thảo luận ở trên Bộ nhận dạng văn bản của ML Kit phân đoạn văn bản thành các khối, dòng và thành phần.
Hình ảnh không chứa hoặc chứa nhiều TextBlock.
TextBlock không chứa hoặc chứa nhiều Line.
Line không chứa hoặc chứa nhiều Element.
Image
|
|___ TextBlock
| |
| |___ Line
| |
| |___ Element
|
|___ TextBlock
|
|___ Line
| |
| |___ Element
| |
| |___ Element
|
|___ Line
|
|___ Element
Bạn có thể trích xuất tất cả thông tin như thế này.
val resultText = result.text
for (block in result.textBlocks) {
val blockText = block.text
val blockConfidence = block.confidence
val blockCornerPoints = block.cornerPoints
val blockFrame = block.boundingBox
for (line in block.lines) {
val lineText = line.text
val lineConfidence = line.confidence
val lineCornerPoints = line.cornerPoints
val lineFrame = line.boundingBox
for (element in line.elements) {
val elementText = element.text
val elementConfidence = element.confidence
val elementCornerPoints = element.cornerPoints
val elementFrame = element.boundingBox
}
}
}
Đây là thành quả đạt được

Mã nguồn đầy đủ:
Theo dõi VnCoder trên Facebook, để cập nhật những bài viết, tin tức và khoá học mới nhất!