


















- Bài 1: MongoDB - Tổng quan
- Bài 2: MongoDB - Điểm mạnh và lợi thế
- Bài 3: MongoDB - Thiết lập môi trường
- Bài 4: MongoDB - Mô hình dữ liệu
- Bài 5: MongoDB - Tạo Database
- Bài 6: MongoDB - Xoá Database
- Bài 7: MongoDB - Tạo Collection
- Bài 8: MongoDB - Xoá Colleciton
- Bài 9: MongoDB - Kiểu dữ liệu
- Bài 10: MongoDB - chèn Document
- Bài 11: MongoDB - truy vấn Document
- Bài 12: MongoDB - Cập nhật Document
- Bài 13: MongoDB - Xoá Document
- Bài 14: MongoDB - Projection
- Bài 15: MongoDB - Giới hạn bản ghi
- Bài 16: MongoDB - Sắp xếp bản ghi
- Bài 17: Mongodb - Index
- Bài 18: MongoDB - Aggregation
- Bài 19: MongoDB - Replication
- Bài 20: MongoDB - Shard
- Bài 21: MongoDB - Tạo backup
- Bài 22: MongoDB - Triển khai
- Bài 23: MongoDB - Java(P1)
- Bài 24: MongoDB - Java(p2)
- Bài 25: MongoDB - PHP
- Bài 26: MongoDB - Relationship
- Bài 27: MongoDB - Tham chiếu database
- Bài 28: MongoDB - Truy vấn Covered
- Bài 29: MongoDB - Phân tích truy vấn
- Bài 30: MongoDB - Toán tử Atomic
- Bài 31: MongoDB - Chỉ mục nâng cao
- Bài 32: MongoDB - Hạn chế chỉ mục (index)
- Bài 33: MongoDB - ObjectID
- Bài 34: MongoDB - Map Reduce
- Bài 35: MongoDB - Text Search
- Bài 36: MongoDB - Regular Expression
- Bài 37: MongoDB - Rockmongo
- Bài 38: MongoDB - GridFS
- Bài 39: MongoDB - Capped Collection
- Bài 40: MongoDB - Auto-Increment
Bài 20: MongoDB - Shard - MongoDB
Đăng bởi: Admin | Lượt xem: 4243 | Chuyên mục: SQL
1. Khái niệm Sharding?
Sharding là một tiến trình lưu giữ các bản ghi dữ liệu qua nhiều thiết bị và nó là một phương pháp của MongoDB để đáp ứng yêu cầu về sự gia tăng dữ liệu. Khi kích cỡ của dữ liệu tăng lên, một thiết bị đơn không thể đủ để lưu giữ dữ liệu. Sharding giải quyết vấn đề này với việc mở rộng phạm vi theo bề ngang (horizontal scaling). Với Sharding, bạn bổ sung thêm nhiều thiết bị để hỗ trợ cho việc gia tăng dữ liệu và các yêu cầu của các hoạt động đọc và ghi.
2. Tại sao sử dụng Sharding?
Trong Replication, tất cả hoạt động ghi thực hiện ở node sơ cấp.
Các truy vấn tiềm tàng vẫn đến node sơ cấp.
Một Replica Set đơn có giới hạn là 12 node.
Bộ nhớ không thể đủ lớn khi tập dữ liệu hoạt động là lớn.
Local Disk là không đủ lớn.
Việc mở rộng phạm vi theo chiều dọc (vertical scaling) là quá tốn kém.
3. Sharding trong MongoDB
Cơ sở dữ liệu với lượng dữ liệu lớn hoặc tải cao là một thách thức lớn đối với mô hình máy chủ đơn(Mainframe).
Với các câu lệnh truy vấn phức tạp có thể làm CPU tăng cao. Với việc phải làm việc với dữ liệu lớn có thể đòi hỏi lượng RAM của máy chủ.
Hiện nay có 2 phương án có thể giải quyết vấn đề trên là: Vertical Scaling và Horizontal Scaling
- Vertical Scaling(Scaling Up): tăng số lõi CPU hoặc là dùng CPU mạnh hơn
- Horizontal Scaling(Scaling Out) : tăng số máy chủ.
Sharding là một phương pháp để lưu trữ dữ liệu (storage) của DB trên nhiều máy chủ. MongoDB sử dụng sharding để hỗ trợ việc phân tán một lượng dữ liệu trên nhiều máy chủ, ở đây có thể là các tập collection trong DB điều này giúp cho việc truy cập nhanh hơn, giảm tải việc quá tải ổ cứng cho một vài máy chủ và giúp hệ thống dễ dàng mở rộng khi có nhu cầu hơn.
Ví dụ, nếu một cơ sở dữ liệu có một bộ dữ liệu 1 terabyte, và có chia ra thành 4 shards, sau đó mỗi shard có thể giữ chỉ 256GB dữ liệu. Nếu có 40 shard thì mỗi shard có thể giữ chỉ 25GB dữ liệu như hình dưới. Điều này giảm dữ liệu mỗi máy chủ phải chứa và dễ dàng có thể mở rộng hệ thống theo chiều ngang.
Sharded Cluster
Mongodb Sharded Cluster bao gồm các thành phần chính như sau:
- Shards: Là nơi chứa dữ liệu, được phân tán bởi nhiều máy chủ theo cơ chế “replica set”
- Query routers: Là nơi điều hướng việc client truy cập chính xác dữ liệu vào shard nào, mỗi hệ thống Sharding có thể có nhiều query router.
- Config servers: Là nơi chưa các “meta data” (nôm na là các thông số kỹ thuật) hệ thống Sharding, nó chứa một bản đồ dữ liệu của việc thiết lập các Shards. Query routers dùng các “meta data” này xác định được chính xác việc truy vấn vào Shards nào trên hệ thống. Mỗi hệ thống Sharding có chính xác là 3 file Config servers.
Với các câu lệnh truy vấn phức tạp có thể làm CPU tăng cao. Với việc phải làm việc với dữ liệu lớn có thể đòi hỏi lượng RAM của máy chủ.
Hiện nay có 2 phương án có thể giải quyết vấn đề trên là: Vertical Scaling và Horizontal Scaling
- Vertical Scaling(Scaling Up): tăng số lõi CPU hoặc là dùng CPU mạnh hơn
- Horizontal Scaling(Scaling Out) : tăng số máy chủ.
Sharding là một phương pháp để lưu trữ dữ liệu (storage) của DB trên nhiều máy chủ. MongoDB sử dụng sharding để hỗ trợ việc phân tán một lượng dữ liệu trên nhiều máy chủ, ở đây có thể là các tập collection trong DB điều này giúp cho việc truy cập nhanh hơn, giảm tải việc quá tải ổ cứng cho một vài máy chủ và giúp hệ thống dễ dàng mở rộng khi có nhu cầu hơn.
Ví dụ, nếu một cơ sở dữ liệu có một bộ dữ liệu 1 terabyte, và có chia ra thành 4 shards, sau đó mỗi shard có thể giữ chỉ 256GB dữ liệu. Nếu có 40 shard thì mỗi shard có thể giữ chỉ 25GB dữ liệu như hình dưới. Điều này giảm dữ liệu mỗi máy chủ phải chứa và dễ dàng có thể mở rộng hệ thống theo chiều ngang.
Sharded Cluster
Mongodb Sharded Cluster bao gồm các thành phần chính như sau:
- Shards: Là nơi chứa dữ liệu, được phân tán bởi nhiều máy chủ theo cơ chế “replica set”
- Query routers: Là nơi điều hướng việc client truy cập chính xác dữ liệu vào shard nào, mỗi hệ thống Sharding có thể có nhiều query router.
- Config servers: Là nơi chưa các “meta data” (nôm na là các thông số kỹ thuật) hệ thống Sharding, nó chứa một bản đồ dữ liệu của việc thiết lập các Shards. Query routers dùng các “meta data” này xác định được chính xác việc truy vấn vào Shards nào trên hệ thống. Mỗi hệ thống Sharding có chính xác là 3 file Config servers.
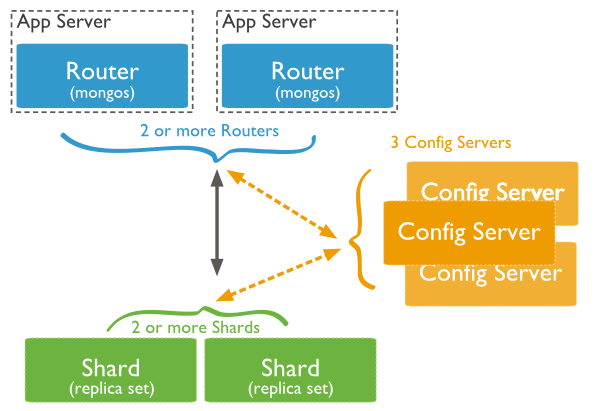
Trong sơ đồ trên, có ba thành phần chính:
Shards: được sử dụng để lưu giữ dữ liệu. Chúng cung cấp tính khả dụng cao và dữ liệu có tính đồng nhất. Trong môi trường tạo lập, mỗi Shard là một Replica Set riêng biệt.
Config Servers: lưu giữ metadata của Cluster. Dữ liệu này chứa một ánh xạ của tập dữ liệu của Cluster tới Shards. Query Router sử dụng metadata này để hướng các hoạt động tới Shards cụ thể. Trong môi trường tạo lập, sharded clusters có chính xác 3 Config Servers.
Query Routers: về cơ bản nó là mongo instance, giao diện với Ứng dụng Client và hướng các hoạt động tới Shard phù hợp. Query Router xử lý và hướng các hoạt động tới Shard và sau đó trả kết quả về Clients. Một Sharded Cluster có thể chứa nhiều hơn một Query Router để phân chia việc tải yêu cầu từ Client. Một Client gửi các yêu cầu tới một Query Router. Nói chung, một Sharded Cluster có nhiều Query Routers.
Mongodb chia sẻ dữ liệu ở tầng Collection(Tương ứng với Table trong hệ quản trị cơ sở dữ liệu quan hệ). Dữ liệu trong Collection được phân tán trên các Shards trong cụm.
Shard Keys: Để phân tán dữ liệu của Collection trên các Shards, MongoDb phân vùng dữ liệu thông qua Shard Keys. Shard Key là một cột hoặc một cụm các cột không thể thay đổi tồn tại ở mỗi Documents thuộc Collection. Chúng ta cần phải chọn một Shard Keys mỗi khi chúng ta phân chia dữ liệu của Collection.
Tất các các Shard Collection bắt buộc phải tạo Index cho Shard Keys. Index này có thể dựa trên field hoặc một tập hợp các fields của Key. Đối với các Collection không có dữ liệu, MongoDB sẽ tự tạo index trên Shard Key nếu như Index không tồn tại.
Lưu ý: Việc chọn lựa Shard Key có ảnh hưởng đến hiệu năng, khả năng mở rộng của Cluster.
MongoDb hỗ trợ Database tồn tại cả 2 loại Sharding Collection và Non Sharding Collection
Chunk: MongoDb phân chia dữ liệu Sharding Collection vào trong chunk. Mặc định Chunk Size là 64Mb.
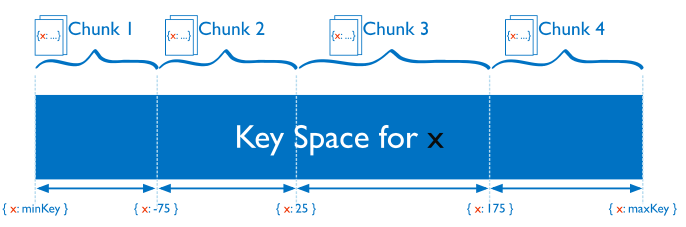
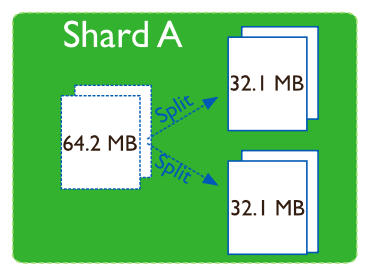
Chunk Splits: Là tiến trình chia cắt khi Chunk tăng đến giới hạn(Chunk Size) hoặc khi số lượng Document trong Chunk vượt quá tham số Maximum Number of Documents Per Chunk to Migrate. Dựa trên Share Key, MongoDb sẽ tiến hành chia cắt thành nhiều Chunk nếu cần
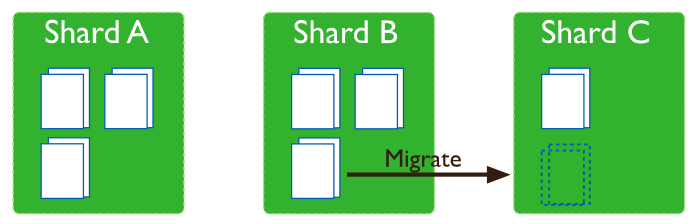
Chunk Migration: MongoDB chuyển đổi Chunk để phân bố lại chunk của Shard Collection. Hình dung việc này cũng như việc chúng ta Defragment lại ổ cứng trên Window. MongoDB cũng hỗ trợ 2 phương pháp để làm được việc này:
- Manual: Chỉ nên sử dụng trong một số trường hợp nhất định như phân tán dữ liệu sử dụng Bulk Insert
- Automatic: Thông qua tiến trình Balancer tự động Migrate lại chunk khi có sự phân bố không đều giữa các chunk trên các Shards
4. Lợi ích của việc sử dụng Sharding:
- Đọc/Ghi: MongoDb phân tán dữ liệu trên các Shards của Cluster. Việc đọc ghi sử dụng Sharding có thể dễ dàng được scaled horizontally
- Lưu trữ(Storage Capacity): Shardings phân tán dữ liệu trên các Shard của Cluster. Việc này giúp cho dữ liệu sẽ được phân bố đều trên cụm máy cài Sharding
- Tính sẵn sàng(High Availability): MongoDB có thể đọc ghi dữ liệu dễ dàng thậm chí ngay cả khi một hoặc nhiều Shard không sẵn sàng. Khi một hoặc nhiều Shard không sẵn sàng, MongoDB vẫn dễ dàng đọc ghi trên nhưng Share sẵn sàng
Theo dõi VnCoder trên Facebook, để cập nhật những bài viết, tin tức và khoá học mới nhất!
- Bài 1: MongoDB - Tổng quan
- Bài 2: MongoDB - Điểm mạnh và lợi thế
- Bài 3: MongoDB - Thiết lập môi trường
- Bài 4: MongoDB - Mô hình dữ liệu
- Bài 5: MongoDB - Tạo Database
- Bài 6: MongoDB - Xoá Database
- Bài 7: MongoDB - Tạo Collection
- Bài 8: MongoDB - Xoá Colleciton
- Bài 9: MongoDB - Kiểu dữ liệu
- Bài 10: MongoDB - chèn Document
- Bài 11: MongoDB - truy vấn Document
- Bài 12: MongoDB - Cập nhật Document
- Bài 13: MongoDB - Xoá Document
- Bài 14: MongoDB - Projection
- Bài 15: MongoDB - Giới hạn bản ghi
- Bài 16: MongoDB - Sắp xếp bản ghi
- Bài 17: Mongodb - Index
- Bài 18: MongoDB - Aggregation
- Bài 19: MongoDB - Replication
- Bài 20: MongoDB - Shard
- Bài 21: MongoDB - Tạo backup
- Bài 22: MongoDB - Triển khai
- Bài 23: MongoDB - Java(P1)
- Bài 24: MongoDB - Java(p2)
- Bài 25: MongoDB - PHP
- Bài 26: MongoDB - Relationship
- Bài 27: MongoDB - Tham chiếu database
- Bài 28: MongoDB - Truy vấn Covered
- Bài 29: MongoDB - Phân tích truy vấn
- Bài 30: MongoDB - Toán tử Atomic
- Bài 31: MongoDB - Chỉ mục nâng cao
- Bài 32: MongoDB - Hạn chế chỉ mục (index)
- Bài 33: MongoDB - ObjectID
- Bài 34: MongoDB - Map Reduce
- Bài 35: MongoDB - Text Search
- Bài 36: MongoDB - Regular Expression
- Bài 37: MongoDB - Rockmongo
- Bài 38: MongoDB - GridFS
- Bài 39: MongoDB - Capped Collection
- Bài 40: MongoDB - Auto-Increment